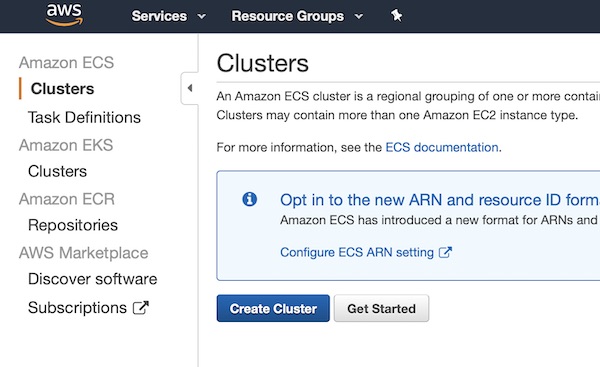
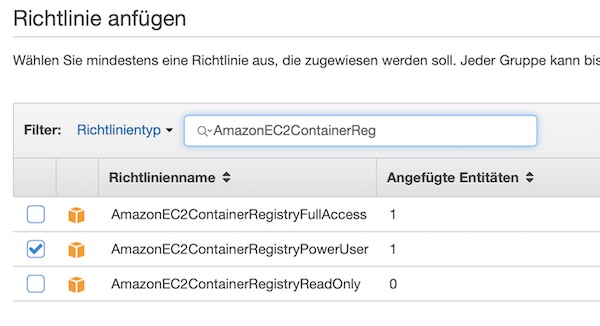
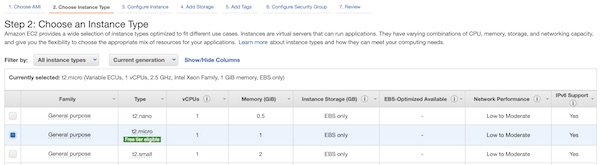
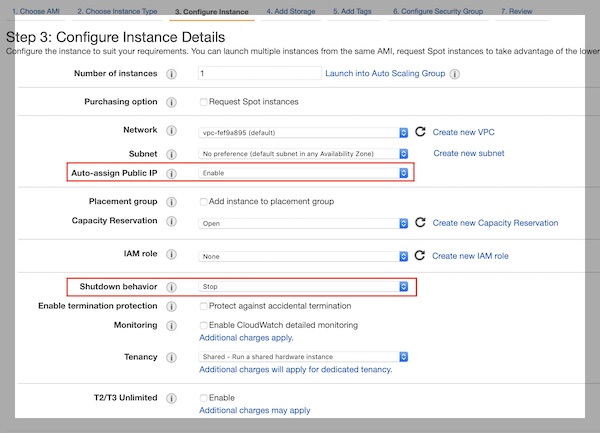
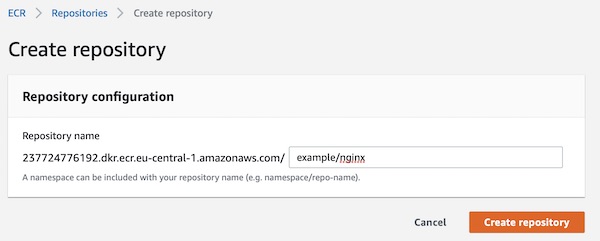
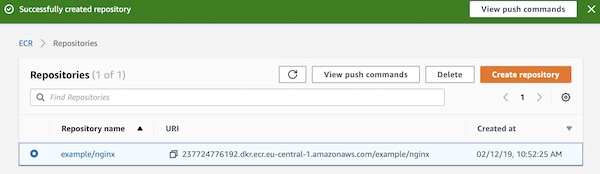
Apache Guacamole … What is it about? It’s a client-less remote gateway for Telnet, SSH, RDP and VNC. Client-less, because there is no need to install any plugin or additional software for users (clients). The client will use just the browser (also without any plugin). In this tutorial we will create a very simple environment via Vagrant and use Guacamole. Why the tutorial? Because I know a lot of testers for example – who work with Windows, who are not allowed to install any software (eq Putty) but still need access to environments. … Next point are for example public security groups on cloud providers. Here only one port would be needed to support different protocols on different hosts (incl. file transfer).
What we need?
- VirtualBox installed (latest)
- Vagrant installed (latest)
Project preparation
# create project
$ mkdir -p ~/Projects/Guacamole/src
# change directory
$ cd ~/Projects/Guacamole/
# create needed files in root folder
$ touch {Vagrantfile,ShellProvisioner.sh}
# create needed files in root folder
$ touch ./src/{guacamole.properties,server.xml,user-mapping.xml,Xwrapper.config}
# show project (optional)
$ tree ~/Projects/Guacamole/
|____src
| |____guacamole.properties
| |____server.xml
| |____user-mapping.xml
| |____Xwrapper.config
|____ShellProvisioner.sh
|____VagrantfileOkay, via your favorite editor you now add the content of all files. All files inside directory “src” are configuration files (installed on Guacamole host).
# Hostname and port of guacamole proxy
guacd-hostname: localhost
guacd-port: 4822
available-languages: en, de
auth-provider: net.sourceforge.guacamole.net.basic.BasicFileAuthenticationProvider
basic-user-mapping: /etc/guacamole/user-mapping.xml
<?xml version="1.0" encoding="UTF-8"?>
<Server port="-1" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<Service name="Catalina">
<Connector port="55555" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>This file (user-mapping.xml) is the configuration for all your connections.
<user-mapping>
<authorize username="USERNAME" password="PASSWORD">
<!--
<connection name="Debian2: RDP Connection">
<protocol>rdp</protocol>
<param name="hostname">localhost</param>
<param name="port">3389</param>
</connection>
-->
<connection name="Debian2: VNC Connection">
<protocol>vnc</protocol>
<param name="hostname">localhost</param>
<param name="port">5901</param>
<param name="password">vagrant</param>
</connection>
<connection name="Debian2: SSH Connection">
<protocol>ssh</protocol>
<param name="hostname">localhost</param>
<param name="port">22</param>
<param name="username">vagrant</param>
</connection>
<connection name="Debian1: SSH Connection">
<protocol>ssh</protocol>
<param name="hostname">192.168.10.5</param>
<param name="port">22</param>
<param name="username">vagrant</param>
</connection>
<connection name="Debian2: Telnet Connection">
<protocol>telnet</protocol>
<param name="hostname">localhost</param>
<param name="port">23</param>
<param name="username">vagrant</param>
</connection>
</authorize>
</user-mapping>allowed_users=anybodyThe ShellProvisioner.sh includes all installation and configuration for Guacamole All examples are provided but for Debian RDP is currently not working and I commented out.
echo '>>>>Install some default packages<<<<<'
sudo apt update -y -q
sudo apt install -y -q build-essential htop libcairo2-dev libjpeg62-turbo-dev libjpeg-dev libpng-dev libossp-uuid-dev
# install optional guacamole packages eq FFmpeg, SSH
sudo apt install -y -q libavcodec-dev libavutil-dev libswscale-dev libpango1.0-dev libssh2-1-dev libssl-dev libvorbis-dev libwebp-dev
echo '>>>>Install and configure tomcat packages<<<<<'
sudo apt install -y -q tomcat9 tomcat9-admin tomcat9-common tomcat9-user
sudo mkdir -p /usr/share/tomcat9/.guacamole
sudo cp /tmp/guacamole/server.xml /etc/tomcat9/server.xml
sudo chown root:tomcat /etc/tomcat9/server.xml
sudo chmod 0640 /etc/tomcat9/server.xml
echo '>>>>Configure default guacamole directory structure<<<<<'
sudo cp -r /tmp/guacamole /etc/guacamole
sudo mkdir -p /etc/guacamole/{extensions,lib}
sudo chown -R root:root /etc/guacamole
sudo chmod 0640 /etc/guacamole/user-mapping.xml
sudo chown root:tomcat /etc/guacamole/user-mapping.xml
sudo ln -s /etc/guacamole/guacamole.properties /var/lib/tomcat9/.guacamole
echo '>>>>Install and configure telnet packages<<<<<'
sudo apt install -y -q telnetd libtelnet-dev
echo '>>>>Install and configure xrdp packages<<<<<'
# actualy broken becauce of freerdp2-dev on debian
# sudo apt install -y -q xrdp freerdp2-dev
# sudo cp /etc/guacamole/Xwrapper.config /etc/X11/Xwrapper.config
# sudo chown root:root /etc/X11/Xwrapper.config
# sudo chmod 0644 /etc/X11/Xwrapper.config
# sudo systemctl enable xrdp.service
# sudo systemctl enable xrdp-sesman.service
# sudo systemctl start xrdp
# sudo systemctl start xrdp-sesman
echo '>>>>Install and configure vnc packages'
sudo apt install -y -q xfce4 xfce4-goodies gnome-icon-theme tightvncserver libvncserver-dev libpulse-dev
echo '>>>>Install guacamole client and restart tomcat<<<<<'
curl -s -O -J -L "http://apache.org/dyn/closer.cgi?action=download&filename=guacamole/1.0.0/binary/guacamole-1.0.0.war"
sudo cp guacamole-1.0.0.war /var/lib/tomcat9/webapps/guacamole.war
sudo chown tomcat:tomcat /var/lib/tomcat9/webapps/guacamole.war
sudo systemctl restart tomcat9
echo '>>>>Install guacamole server<<<<<'
curl -s -O -J -L "http://apache.org/dyn/closer.cgi?action=download&filename=guacamole/1.0.0/source/guacamole-server-1.0.0.tar.gz"
tar xzf guacamole-server-1.0.0.tar.gz
cd guacamole-server-1.0.0/
# space after etc is wrong
sudo ./configure --with-init-dir=/etc /init.d
sudo make
sudo make install
sudo ldconfig
sudo update-rc.d guacd defaults
echo '>>>>Start guacamole server/daemon<<<<<'
sudo systemctl start guacd
echo '>>>>Show open ports<<<<<'
sudo lsof -i -P -n | grep LISTEN
echo '>>>>Start clean-up<<<<<'
sudo rm /etc/guacamole/Xwrapper.config
sudo rm /etc/guacamole/server.xml
sudo rm -fr /tmp/guacamole
sudo rm -fr /home/vagrant/guacamole-server-1.0.0s
sudo rm /home/vagrant/guacamole-server-1.0.0.tar.gz
sudo rm /home/vagrant/guacamole-1.0.0.war# -*- mode: ruby -*-
# vi: set ft=ruby :
BOX_1_NAME = "debian-1-guacamole"
BOX_2_NAME = "debian-2-guacamole"
BOX_BASE = "generic/debian10"
BOX_RAM_MB = 1024
BOX_CPU_COUNT = 1
BOX_GUI = false
BOX_SYNC_DIR = true
Vagrant.configure("2") do |config|
config.vm.define BOX_1_NAME do |deb1|
deb1.vm.box = BOX_BASE
deb1.vm.synced_folder ".", "/vagrant", disabled: BOX_SYNC_DIR
deb1.vm.hostname = BOX_1_NAME
deb1.vm.network "private_network", ip: "192.168.10.5"
deb1.vm.provider "virtualbox" do |vb1|
vb1.name = BOX_1_NAME
vb1.cpus = BOX_CPU_COUNT
vb1.memory = BOX_RAM_MB
vb1.gui = BOX_GUI
end
end
config.vm.define BOX_2_NAME do |deb2|
deb2.vm.box = BOX_BASE
deb2.vm.synced_folder ".", "/vagrant", disabled: BOX_SYNC_DIR
deb2.vm.hostname = BOX_2_NAME
deb2.vm.network "forwarded_port", guest: 55555, host: 55555
# deb2.vm.network "forwarded_port", guest: 5901, host: 5901
# deb2.vm.network "forwarded_port", guest: 3389, host: 3389
# deb2.vm.network "forwarded_port", guest: 23, host: 2323
deb2.vm.network "private_network", ip: "192.168.10.10"
deb2.vm.provider "virtualbox" do |vb2|
vb2.name = BOX_2_NAME
vb2.cpus = BOX_CPU_COUNT
vb2.memory = BOX_RAM_MB
vb2.gui = BOX_GUI
end
deb2.vm.provision "file", source: "./src", destination: "/tmp/guacamole"
deb2.vm.provision "shell", name: "install", path: "./ShellProvisioner.sh"
end
end
Usage
First start-up the environment (via simple Vagrant command) and next start the VNC inside the box. You can do via vagrant ssh or you start the VNC via Browser (SSH).
# start environment (be patient)
$ vagrant up
# show status (optional)
$ vagrant status
# ssh into 2nd box
$ vagrant ssh debian-2-guacamole
# start VNC server on user vagrant
$ vncserver
# Password: vagrant
# Verify: vagrant
# Would you like to enter a view-only password (y/n)? n
# exit ssh into box
$ exit
# open browser with URL
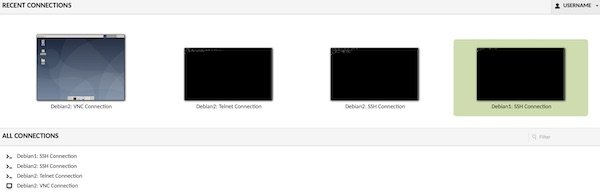
$ open http://localhost:55555/guacamoleNow login with “USERNAME/PASSWORD” (see src/user-mapping.xml) on http://localhost:55555/guacamole. If everything works it should look like this:
Please have a look here https://guacamole.apache.org/doc/gug/index.html to learn more about configuration and authentication. All files which we used in this tutorial are available via https://github.com/Lupin3000/GuacamoleExample.