This tutorial will explain how easy you implement ZAP Attack Proxy into Jenkins. Therefor we create a Freestyle job and will use the “Official OWASP ZAP Jenkins Plugin“. That you can follow and reproduce the tutorial, you need a running Jenkins instance with SSH access to it and proper system rights (OS, Jenkins).
Install ZAP Attack Proxy
Following steps needs to be done when SSH connection, to Jenkins, is established.
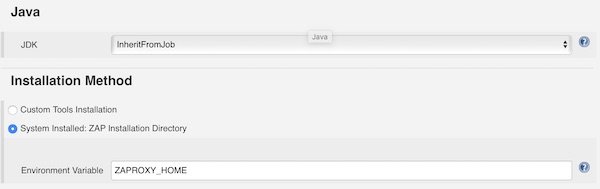
Note: If you don’t restart Jenkins after creating “ZAPROXY_HOME”, you will run into trouble like “java.lang.IllegalArgumentException: ZAP INSTALLATION DIRECTORY IS MISSING, PROVIDED [ null ]”
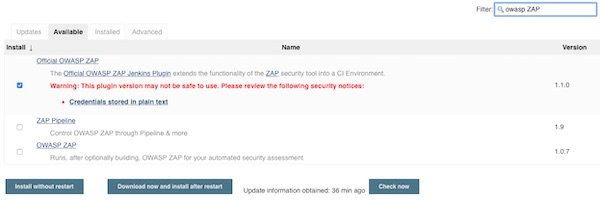
Install needed Jenkins PlugIn’s
Search for “OWAS ZAP” and for “HTML Publisher” plugins.
Official OWASP ZAP HTML Publisher
Configure Jenkins Freestyle job
All what we need is there, we can start to setup a Jenkins “Freestyle project” with the name “ZAPAttackProxy”.
Jenkins Freestyle Project
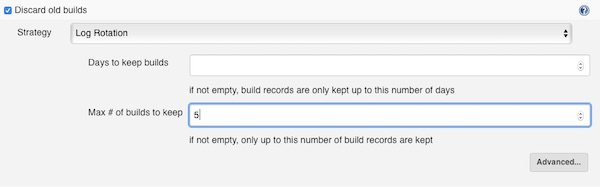
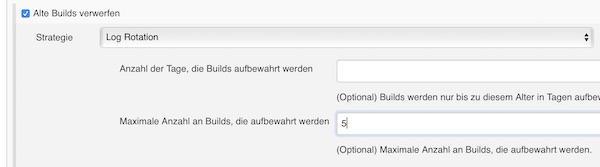
The next setting is optional… I recommend to find your own value (I go with 5 for that example).
Max # of builds to keep
On every build (Jenkins job run) the workspace should be clean. Please enable the checkbox.
Delete workspace before build starts
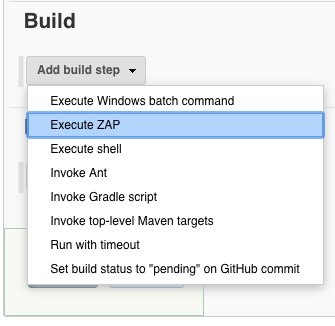
We add now the build step. This build step is available because of the PlugIn “Official OWASP ZAP“.
Build step: Execute ZAP
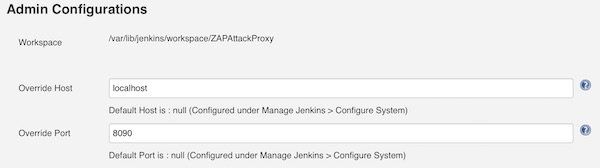
Now we have many fields to configure. We start to set the values for section “Admin Configurations”.
Admin Configuration
As we already installed ZAP and created the entry into /etc/environment, we can now use that variable.
Installation Method
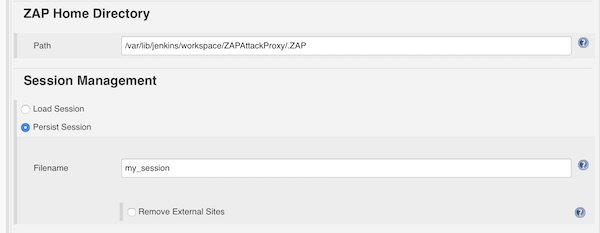
For ZAP Home Directory we add the path to the workspace and let the build create the directory “.ZAP”. For Session Management we choose “Persist Session” and give filename “my_session”.
Home Directory & Session Management
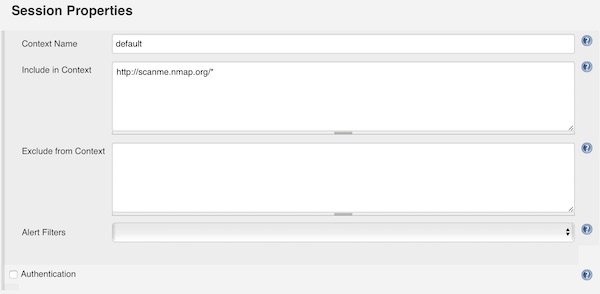
Under section “Session Properties” you add the Context Name “default” and for “Include in Context” you can add IP’s and/or Domains. For that example I choose “http://scanme.nmap.org/*”.
Session Properties
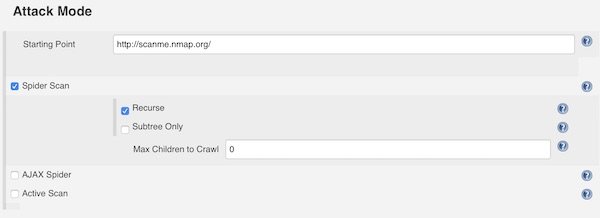
In section “Attack Method” you can choose different attack methods like Spider Scan and so on. Please set always a “Starting Point”. The settings here are self explainable.
Attack Method
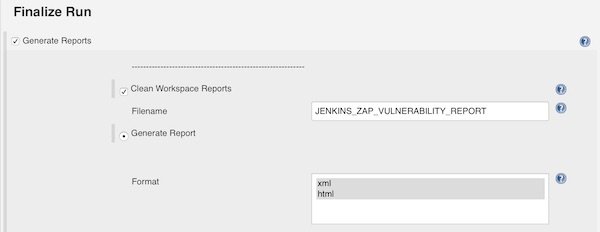
Enable checkbox “Generate Reports” in section “Finalize Run”. Now enter a filename and select “XML” and “HTML” format.
Finalize Run
Note: You can ignore the HTTP 404 error.
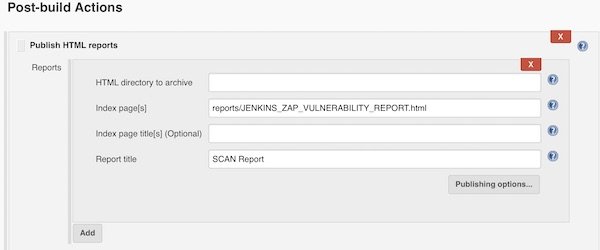
We are done! To provide on our job dashboard a link for HTML report, you can use now the HTML Publisher.
Nessus is a vulnerability scanner from Tenable. In this tutorial I will show how you can install Nessus on AWS (Debian), how you connect your local browser and perform a simple network scan. You need only a AWS account (eq Free Tier), SSH and a web browser.
Note: Please have a look on that page about pentesting on AWS first.
Create new EC2 instance
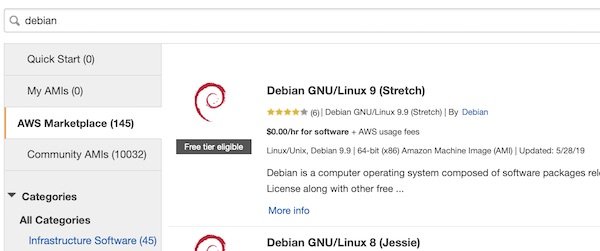
Login into your AWS console (or use AWSCLI), create a new SecurityGroup with SSH port 22 only (inbound) and launch a new instance. Search for “Debian”…
Debian 9 on AWS Maretplace
Press button “Select” and finish all needed following steps (save your keys). After your EC2 instance is ready check for IP or DNS and connect.
# connect via SSH to EC2 instance
$ ssh -i ~/.ssh/ admin@<instance>
# compile a list of locale definition files (optional)
$ sudo locale-gen UTF-8
Install Nessus
Open download page and select latest version for Debian (as I wrote this tutorial it was Nessus-8.5.1-debian6_amd64.deb). Confirm and download. Via SCP, in new terminal, you can upload the file to your EC2 instance.
# copy file from local to remote
$ scp -i ~/.ssh/ ~/Downloads/Nessus-8.5.1-debian6_amd64.deb admin@<instance>:/tmp
Back to instance terminal … Now install and start Nessus.
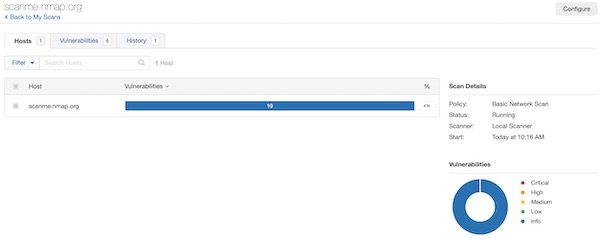
When the initialization has been completed successfully, login and create a new scan. Select “Basic Network Scan” and add URL: http://scanme.nmap.org. Select “Basic Network Scan” and “Port scan (common ports)” for scan settings. Save and start your created scan. Please be patient, the scan will take a while.
Running Nessus scan
Create a scan report
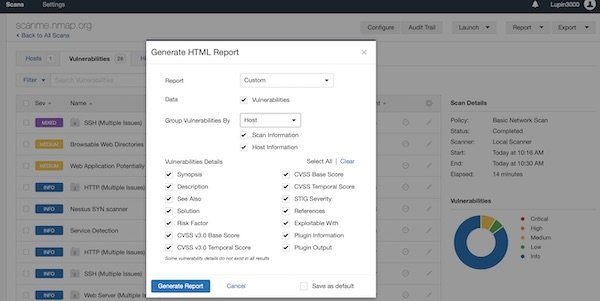
After a while, the scan is complete. Now you can create a “Custom” report. BTW … feature is only available for completed scans. So select “Export” – “Custom” and generate the report.
Apache Guacamole … What is it about? It’s a client-less remote gateway for Telnet, SSH, RDP and VNC. Client-less, because there is no need to install any plugin or additional software for users (clients). The client will use just the browser (also without any plugin). In this tutorial we will create a very simple environment via Vagrant and use Guacamole. Why the tutorial? Because I know a lot of testers for example – who work with Windows, who are not allowed to install any software (eq Putty) but still need access to environments. … Next point are for example public security groups on cloud providers. Here only one port would be needed to support different protocols on different hosts (incl. file transfer).
Okay, via your favorite editor you now add the content of all files. All files inside directory “src” are configuration files (installed on Guacamole host).
# Hostname and port of guacamole proxy
guacd-hostname: localhost
guacd-port: 4822
available-languages: en, de
auth-provider: net.sourceforge.guacamole.net.basic.BasicFileAuthenticationProvider
basic-user-mapping: /etc/guacamole/user-mapping.xml
The ShellProvisioner.sh includes all installation and configuration for Guacamole All examples are provided but for Debian RDP is currently not working and I commented out.
First start-up the environment (via simple Vagrant command) and next start the VNC inside the box. You can do via vagrant ssh or you start the VNC via Browser (SSH).
# start environment (be patient)
$ vagrant up
# show status (optional)
$ vagrant status
# ssh into 2nd box
$ vagrant ssh debian-2-guacamole
# start VNC server on user vagrant
$ vncserver
# Password: vagrant
# Verify: vagrant
# Would you like to enter a view-only password (y/n)? n
# exit ssh into box
$ exit
# open browser with URL
$ open http://localhost:55555/guacamole
Now login with “USERNAME/PASSWORD” (see src/user-mapping.xml) on http://localhost:55555/guacamole. If everything works it should look like this:
This tutorial will show how to setup a simple test environment via Vagrant and to install, configure and use WireGuard VPN software. In this tutorial Debian 10 is used, you can find the documentation about other OS on WireGuard website.
Preparation
First make sure VirtualBox and Vagrant are installed in latest versions. Now create needed project and files.
# -*- mode: ruby -*-
# vi: set ft=ruby :
require 'yaml'
machines = YAML.load_file('machines.yml')
Vagrant.configure("2") do |config|
machines.each do |machines|
config.vm.define machines["name"] do |machine|
# box settings
machine.vm.hostname = machines["name"]
machine.vm.box = machines["box"]
machine.vm.synced_folder ".", "/vagrant", disabled: true
machine.vm.network "private_network", ip: machines["ip"]
# virtualbox settings
machine.vm.provider :virtualbox do |vb|
vb.name = machines["name"]
vb.cpus = machines["cpus"]
vb.memory = machines["memory"]
vb.gui = false
end
# provision all
machine.vm.provision "shell", name: "all", inline: <<-SHELL
sudo echo "deb http://deb.debian.org/debian/ unstable main" > /etc/apt/sources.list.d/unstable.list
sudo printf 'Package: *\nPin: release a=unstable\nPin-Priority: 90\n' > /etc/apt/preferences.d/limit-unstable
sudo apt update -y && sudo apt install -y wireguard
SHELL
# provision only host-a
if machines["name"] == 'host-a'
machine.vm.provision "shell", name: "host-a only", inline: <<-SHELL
sudo su -
cd ~
wg genkey > private
ip link add wg0 type wireguard
ip addr add 10.0.0.1/24 dev wg0
wg set wg0 private-key ./private
ip link set wg0 up
ip addr
wg
SHELL
end
# provision only host-b
if machines["name"] == 'host-b'
machine.vm.provision "shell", name: "host-b only", inline: <<-SHELL
sudo su -
cd ~
wg genkey > private
wg pubkey < private
ip link add wg0 type wireguard
ip addr add 10.0.0.2/24 dev wg0
wg set wg0 private-key ./private
ip link set wg0 up
ip addr
wg
SHELL
end
end
end
end
Usage
All files are created and we can start to start the environment.
In this tiny tutorial, I would like to introduce SonarQube usage. I will show the usage of SonarQube Server via Docker and will give some hints about the SonarQube Scanner. Therefore we create three very simple example files (html, css and javascript).
You need to download the SonarQube Scanner by your self. You will find it here incl. all important informations.
# download macos version
$ curl -LOJ https://binaries.sonarsource.com/Distribution/sonar-scanner-cli/sonar-scanner-cli-3.3.0.1492-macosx.zip
# unzip and delete
$ unzip sonar-scanner-cli-3.3.0.1492-macosx.zip && rm sonar-scanner-cli-3.3.0.1492-macosx.zip
Note: At this point you could also move the scanner files to the right place and create a symbolic link. I will skip that step and use the path to binary.
Execute sonar-scanner
If not done till now, open SonarQube in your browser (http://localhost:9000) and login with admin/admin.
# create variable with timestamp
$ SCAN_VERSION="$(date +'%s')"
# execute sonar-scanner run
$ sonar-scanner-3.3.0.1492-macosx/bin/sonar-scanner -D sonar.version="$SCAN_VERSION" > sonar_log.txt
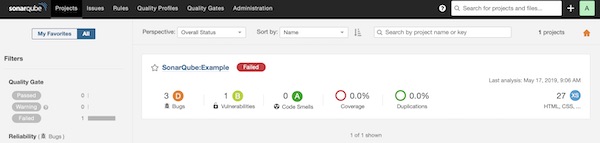
You should now be able to see the result of the scan in SonarQube.
Analyzing the scan from command line
To see the results in SonarQube is perfect but now we will try to get them in our command-line.
# show content of sonar_log.txt (optional)
$ cat sonar_log.txt
# create variable with taskid
$ TASK_ID="$(cat < sonar_log.txt | grep "task?id=" | awk -F "id=" '/id=/{print $2}')"
# show detailed task status (optional)
$ curl -s "http://localhost:9000/api/ce/task?id=$TASK_ID" | jq -r .
# show task status
$ curl -s "http://localhost:9000/api/ce/task?id=$TASK_ID" | jq -r .task.status
# create variable with analysisid
$ ANALYSIS_ID="$(curl -s "http://localhost:9000/api/ce/task?id=$TASK_ID" | jq -r .task.analysisId)"
# show detailed quality gate status (optional)
$ curl -s "http://localhost:9000/api/qualitygates/project_status?analysisId=$ANALYSIS_ID" | jq -r .
# show quality gate status
$ curl -s "http://localhost:9000/api/qualitygates/project_status?analysisId=$ANALYSIS_ID" | jq -r .projectStatus.status
Okay,… The pipeline has already two steps “Build” and “Deploy” running, but the last step “Test” is missing. In this part I will show a simple example with Python, Selenium and Docker (standalone-chrome) for test step.
#!/usr/bin/env bash
## shell options
set -e
set -u
set -f
## magic variables
declare CLUSTER
declare TASK
declare TEST_URL
declare -r -i SUCCESS=0
declare -r -i NO_ARGS=85
declare -r -i BAD_ARGS=86
declare -r -i MISSING_ARGS=87
## script functions
function usage() {
local FILE_NAME
FILE_NAME=$(basename "$0")
printf "Usage: %s [options...]\n" "$FILE_NAME"
printf " -h\tprint help\n"
printf " -c\tset esc cluster name uri\n"
printf " -t\tset esc task name\n"
}
function no_args() {
printf "Error: No arguments were passed\n"
usage
exit "$NO_ARGS"
}
function bad_args() {
printf "Error: Wrong arguments supplied\n"
usage
exit "$BAD_ARGS"
}
function missing_args() {
printf "Error: Missing argument for: %s\n" "$1"
usage
exit "$MISSING_ARGS"
}
function get_test_url() {
local TASK_ARN
local TASK_ID
local STATUS
local HOST_PORT
local CONTAINER_ARN
local CONTAINER_ID
local INSTANCE_ID
local PUBLIC_IP
# list running task
TASK_ARN="$(aws ecs list-tasks --cluster "$CLUSTER" --desired-status RUNNING --family "$TASK" | jq -r .taskArns[0])"
TASK_ID="${TASK_ARN#*:task/}"
# wait for specific container status
STATUS="PENDING"
while [ "$STATUS" != "RUNNING" ]; do
STATUS="$(aws ecs describe-tasks --cluster "$CLUSTER" --task "$TASK_ID" | jq -r .tasks[0].containers[0].lastStatus)"
done
# get container id
CONTAINER_ARN="$(aws ecs describe-tasks --cluster "$CLUSTER" --tasks "$TASK_ID" | jq -r .tasks[0].containerInstanceArn)"
CONTAINER_ID="${CONTAINER_ARN#*:container-instance/}"
# get host port
HOST_PORT="$(aws ecs describe-tasks --cluster "$CLUSTER" --tasks "$TASK_ID" | jq -r .tasks[0].containers[0].networkBindings[0].hostPort)"
# get instance id
INSTANCE_ID="$(aws ecs describe-container-instances --cluster "$CLUSTER" --container-instances "$CONTAINER_ID" | jq -r .containerInstances[0].ec2InstanceId)"
# get public IP
PUBLIC_IP="$(aws ec2 describe-instances --instance-ids "$INSTANCE_ID" | jq -r .Reservations[0].Instances[0].PublicIpAddress)"
TEST_URL="$(printf "http://%s:%d" "$PUBLIC_IP" "$HOST_PORT")"
}
function clean_up() {
# stop container
if [ "$(docker inspect -f {{.State.Running}} ChromeBrowser)" == "true" ]; then
docker rm -f ChromeBrowser
fi
# delete virtualenv
if [ -d .env ]; then
rm -fr .env
fi
}
function run_selenium_test() {
local TEST_TEMPLATE
local TEST_FILE
# clean up
clean_up
# pull image (standalone-chrome)
docker pull selenium/standalone-chrome
# run docker container (standalone-chrome)
docker run -d -p 4444:4444 --name ChromeBrowser selenium/standalone-chrome
# create and activate virtualenv
virtualenv .env && source .env/bin/activate
# install Selenium
pip install -U selenium
# read test template into variable
TEST_TEMPLATE=$(cat ./test/example.py)
# replace string with URL
TEST_FILE="${TEST_TEMPLATE/APPLICATION_URL/$TEST_URL}"
# save into final test file
echo "$TEST_FILE" > ./test/suite.py
# execute test
python -B ./test/suite.py
# deactivate virtualenv
deactivate
}
## check script arguments
while getopts "hc:t:" OPTION; do
case "$OPTION" in
h) usage
exit "$SUCCESS";;
c) CLUSTER="$OPTARG";;
t) TASK="$OPTARG";;
*) bad_args;;
esac
done
if [ "$OPTIND" -eq 1 ]; then
no_args
fi
if [ -z "$CLUSTER" ]; then
missing_args '-c'
fi
if [ -z "$TASK" ]; then
missing_args '-t'
fi
## run main function
function main() {
get_test_url
printf "Test Application URL: %s\n" "$TEST_URL"
run_selenium_test
}
main
# exit
exit "$SUCCESS"
Ensure that “example.py” has all needed permission rights. $ chmod +x example.py Commit all changes now and wait that the Jenkins job gets triggered (or trigger manually).
That’s already all… your job should execute all steps. This part is done super fast. 😉
Some last words
There is a lot of space for improvements here, but I think you learned already much and had some fun. Some hints now:
you can add any other test methods by your self on this step (eq. Performance- and Security tests)
Unit tests and Static Code Analysis could executed on build step (before create image)
check out AWS ECS Services
use a proxy for Jenkins and enable SSL
create other pipelines and ECS clusters to enable staging
create “Lifecycle policy rules” on ECR
use Git Webhook’s to trigger the Jenkins jobs
add a post step in your Jenkins pipeline to store metrics and/or inform about build status
In previous tutorial I showed you how to create the environment and how to implement the build steps for Jenkins pipeline. Now I will show you to setup the deploy step.
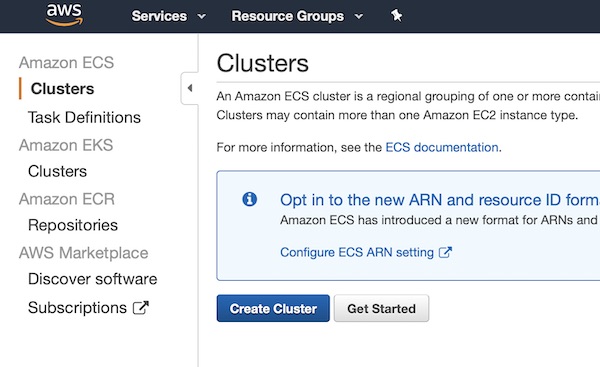
Create a very small AWS ECS cluster in region “Frankfurt” (eu-central-1). Therefore enter Amazon ECS Clusters and press button “Create Cluster”.
Select template “EC2 Linux + Networking” and continue to next step.
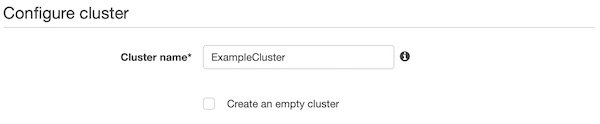
On section “Configure cluster” you give a name like “ExampleCluster”.
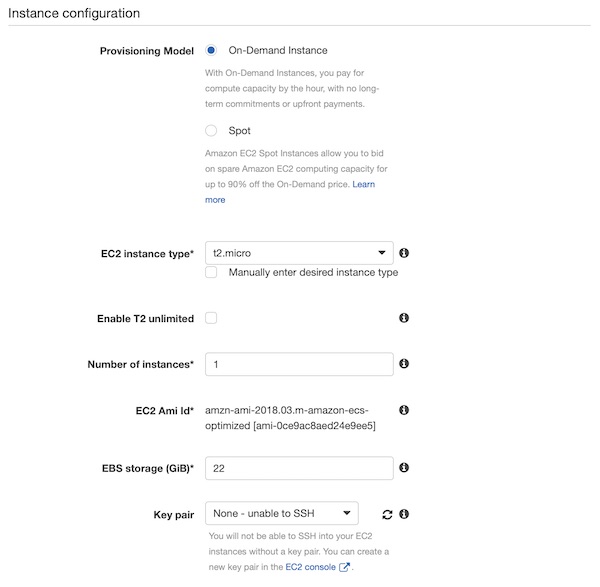
On section “Instance configuration” select “On-Demand Instance”, “t2.micro”, “1”, “22” and “None – unable to SSH”.
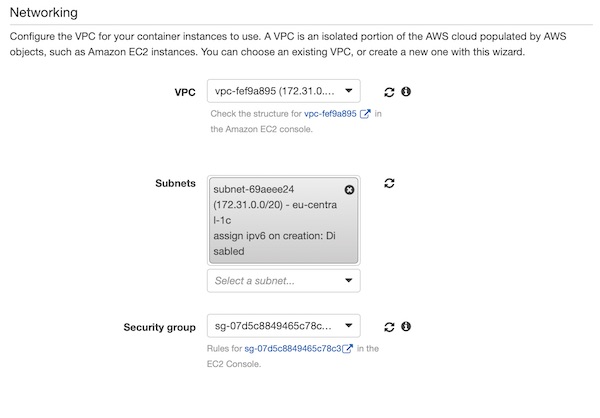
In the section “Networking” you have to be careful now. Your values will be different from mine! Under VPC, select the same value as for the EC2 Jenkins instance (I selected default VPC). Now you can choose one of the subnets. We created the security group together with the EC2 Jenkins instance, so select “ExampleSecurityGroup” here.
Okay, press button “Create” and wait till the cluster is created. The cluster creation can take a while, so please be patient.
AWS ECS Task Definition
The cluster is running and the “Task Definition” can be created. So press button “Create new Task Definition”.
Select “EC2” on page launch type compatibility and press button “Next step”.
On section “Configure task and container definitions” set value “ExampleTask” for input field “Task Definition Name” and for “Network Mode” select “<default>”.
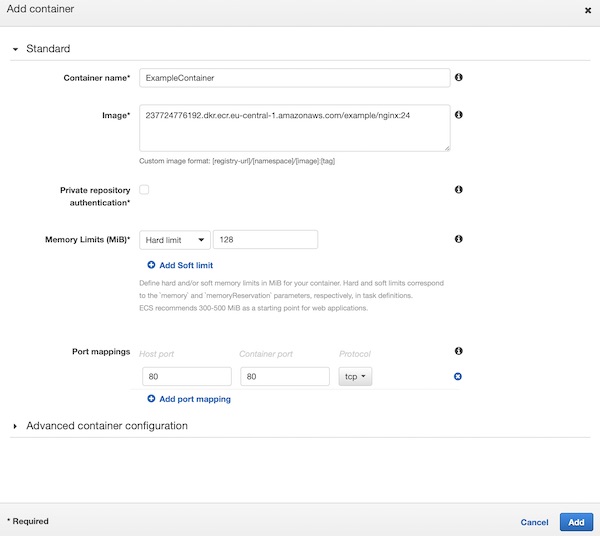
On section “Container Definition” press button “Add Container”. A new window will slide in. Here give the “Container name” value “ExampleContainer”, add under image your latest version from ECR (my latest is 24). Set values “128” for “Memory Limits (MiB)”, “80:80” for “Port mappings” and press button “Add”.
You are done with your task definition configuration, scroll down and press button “Create”.
AWS IAM
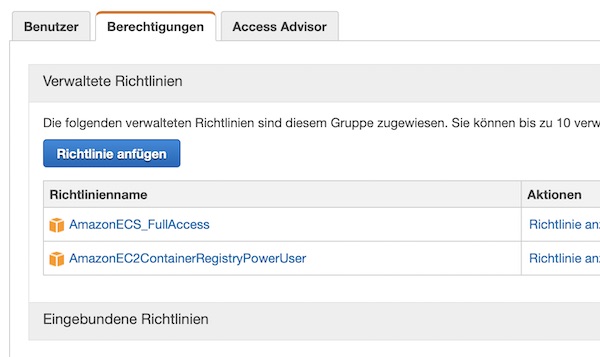
Before we can go through the next steps, we need to adjust the group policy for “PipelineExampleGroup”. You must add the “AmazonECS_FullAccess” policy. _For our example this is okay, but never use this policy in production!_
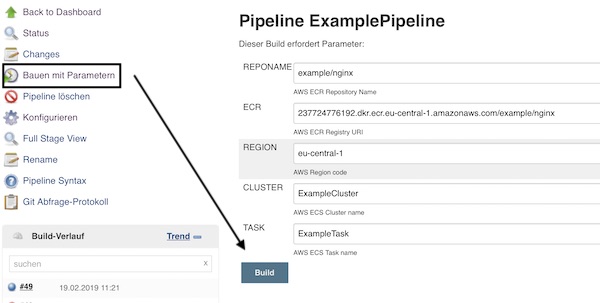
Run task on ECS cluster (via Jenkins)
Now you only need to modify two files in your repository. Replace the content of “deploy.sh” and “Jenkinsfile” with following contents.
#!/usr/bin/env bash
## shell options
set -e
set -u
set -f
## magic variables
declare ECR
declare CLUSTER
declare TASK
declare BUILD_NUMBER
declare -r -i SUCCESS=0
declare -r -i NO_ARGS=85
declare -r -i BAD_ARGS=86
declare -r -i MISSING_ARGS=87
## script functions
function usage() {
local FILE_NAME
FILE_NAME=$(basename "$0")
printf "Usage: %s [options...]\n" "$FILE_NAME"
printf " -h\tprint help\n"
printf " -e\tset ecr repository uri\n"
printf " -c\tset esc cluster name uri\n"
printf " -t\tset esc task name\n"
printf " -b\tset build number\n "
}
function no_args() {
printf "Error: No arguments were passed\n"
usage
exit "$NO_ARGS"
}
function bad_args() {
printf "Error: Wrong arguments supplied\n"
usage
exit "$BAD_ARGS"
}
function missing_args() {
printf "Error: Missing argument for: %s\n" "$1"
usage
exit "$MISSING_ARGS"
}
## check script arguments
while getopts "he:c:t:b:" OPTION; do
case "$OPTION" in
h) usage
exit "$SUCCESS";;
e) ECR="$OPTARG";;
c) CLUSTER="$OPTARG";;
t) TASK="$OPTARG";;
b) BUILD_NUMBER="$OPTARG";;
*) bad_args;;
esac
done
if [ "$OPTIND" -eq 1 ]; then
no_args
fi
if [ -z "$ECR" ]; then
missing_args '-e'
fi
if [ -z "$CLUSTER" ]; then
missing_args '-c'
fi
if [ -z "$TASK" ]; then
missing_args '-t'
fi
if [ -z "$BUILD_NUMBER" ]; then
missing_args '-b'
fi
## run main function
function main() {
local TASK_ARN
local TASK_ID
local ACTIVE_TASK_DEF
local TASK_DEFINITION
local TASK_DEF_ARN
# list running task
TASK_ARN="$(aws ecs list-tasks --cluster "$CLUSTER" --desired-status RUNNING --family "$TASK" | jq -r .taskArns[0])"
TASK_ID="${TASK_ARN#*:task/}"
# stop running task
if [ -n "$TASK_ID" ] && [ "$TASK_ID" != "null" ]; then
printf "INFO: Stop Task %s\n" "$TASK_ID"
aws ecs stop-task --cluster "$CLUSTER" --task "$TASK_ID"
fi
# list active task definition
ACTIVE_TASK_DEF="$(aws ecs list-task-definitions --family-prefix "$TASK" --status ACTIVE | jq -r .taskDefinitionArns[0])"
# derigister task definition
if [ -n "$ACTIVE_TASK_DEF" ]; then
printf "INFO: Deregister Task Definition %s\n" "$ACTIVE_TASK_DEF"
aws ecs deregister-task-definition --task-definition "$ACTIVE_TASK_DEF"
fi
# read task definition template
TASK_DEFINITION=$(cat ./cicd/task_definition.json)
# create new task definition file
TASK_DEFINITION="${TASK_DEFINITION/URI/$ECR}"
echo "${TASK_DEFINITION/NUMBER/$BUILD_NUMBER}" > ecs_task_definition.json
# register new task definition
TASK_DEF_ARN="$(aws ecs register-task-definition --cli-input-json file://ecs_task_definition.json | jq -r .taskDefinition.taskDefinitionArn)"
# run task by task definition
aws ecs run-task --task-definition "$TASK_DEF_ARN" --cluster "$CLUSTER"
}
main
# exit
exit "$SUCCESS"
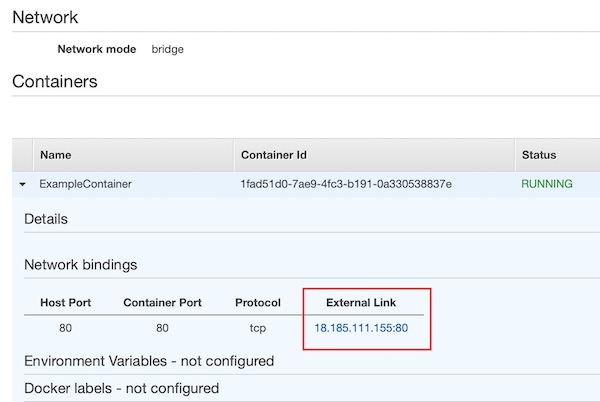
Commit your changes and wait for build trigger (or trigger manually). After successful deployment, your ECS cluster will have a running task now. On section “Container” you can see the link.
Every time when you modify files and commit them into your Git repository, the pipeline will be triggered and latest version will be visible in browser.
That’s it with this part of the series. Cu soon in next part.
This tutorial serie should enable you to create own pipelines via Jenkins on AWS. Therefore we try to catch all needed basics with AWS IAM, EC2, ECR and ECS. Some of our configurations are recommended only for learning purpose, don’t use them on production! Why? Because these lessons are for people who starts on these topics and I will try to make all steps/configuration as easy as possible without focus on security. In this part we will create the environment and setup the “build step”.
Preconditions
AWS account (eq. free tier)
Git account (eq. GitLab, Bitbucket, GitHub, etc.)
AWS IAM
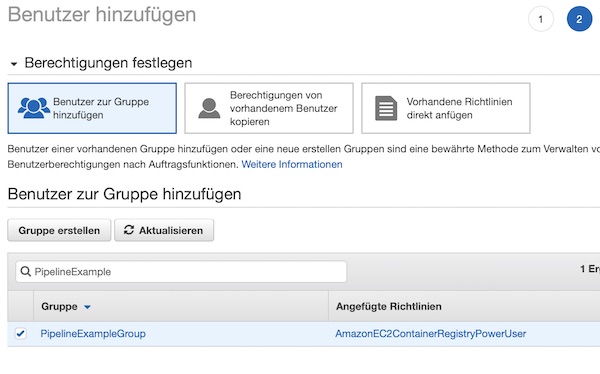
The first preparation you do on AWS IAM Management Console. Here you create and configure a new group. The benefit of this group is that you can reconfigure the policies for assigned users easily at anytime. Please name the group “PipelineExampleGroup”.
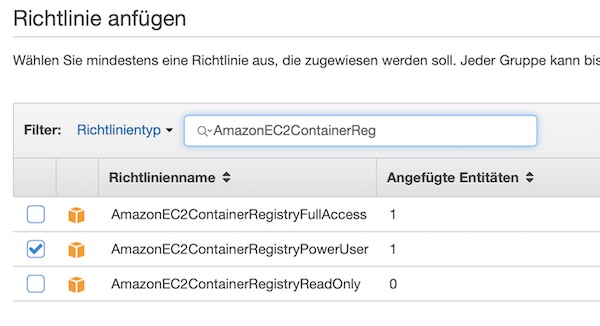
Now search for EC2 Container Registry policies and enable checkbox for “AmazonEC2ContainerRegistryPowerUser”. For our example this policy is enough, but for production please don’t do that!
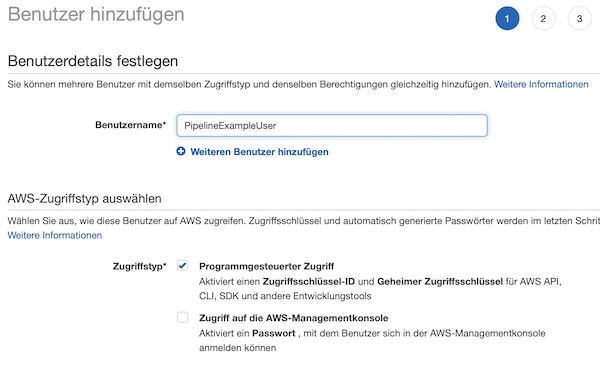
After the group is created, a user needs to be assigned to this group. Name the user “PipelineExampleUser”. Please enable checkbox “Programmatic access” for this user.
Assign the user to group.
Before you finish the process, please choose Download .csv and then save the file to a safe location.
AWS Jenkins EC2 Instance
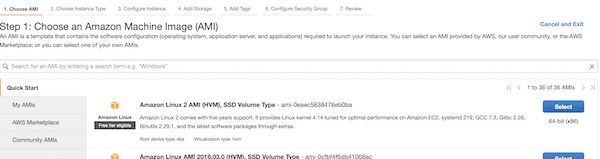
Now you can launch our EC2 instance. Do this on region “Frankfurt” (eu-central-1). Of course you can choose any other region, but please remember your choice later. At very first step select the template “Amazon Linux 2 AMI (HVM), SSD Volume Type”.
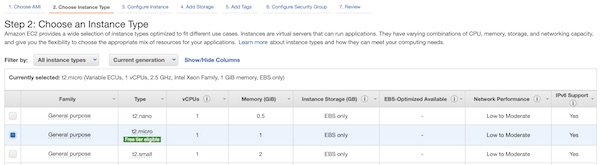
The instance type “t2.micro” is enough for our example. For production you will need something else – depending to your needs.
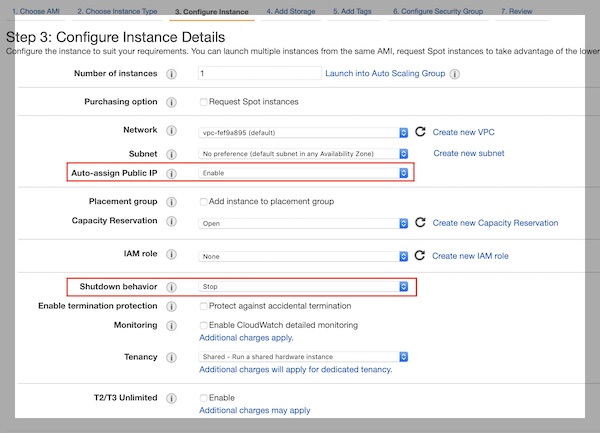
Now you need to be a little bit careful. On Instance Details step please select “Enable” for “Auto-assign Public IP” and “Stop” for “Shutdown Behavior”. For all other values the defaults should be fine. I select my default VPC and “No preference…” for Subnet.
15 Gb disk space are fine. For production you need to estimate differently.
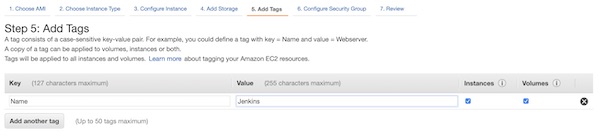
With the tag you will have it easier to identify the instance later on console view. Enter values “Name” for “Key” and “Jenkins” for “Value”.
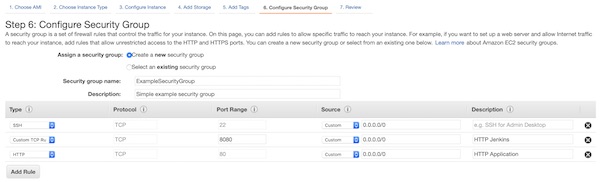
Create a new security group with name “ExampleSecurityGroup” and allow ports 22, 80 and 8080 (IPv4 only). You can change the configuration at any time later. On a production environment you should use other ports like 443 and IP restrictions.
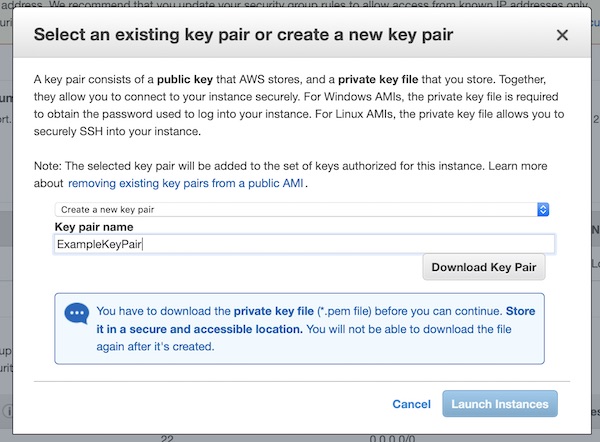
Create a new key pair with name “ExampleKeyPair”. Don’t forget to save the key (“Download Key Pair”) and press “Launch Instances”!
Install and run Jenkins
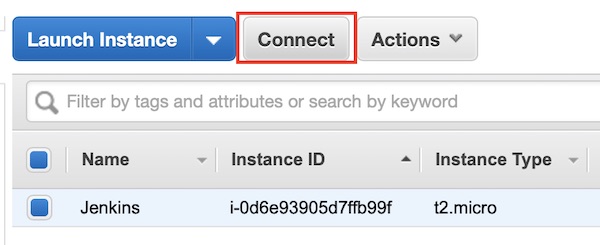
The EC2 instance is running and you can connect via SSH to start all needed installations and configurations. Attention: Your Public IP/DNS will be different (also after every stop/start), via button “Connect” you can easily figure out your configuration. I will just use the term “<EC2 IP|DNS>” in my description.
# move SSH keys (my are downloaded under Downloads)
$ mv ~/Downloads/ExampleKeyPair.pem.txt ~/.ssh/ExampleKeyPair.pem
# change permissions
$ chmod 0400 ~/.ssh/ExampleKeyPair.pem
# start ssh connection
$ ssh -i ~/.ssh/ExampleKeyPair.pem ec2-user@<EC2 IP|DNS>
# change to root user
$ sudo su -
# update system
$ yum update -y
# add latest Jenkins repository
$ wget -O /etc /yum.repos.d/jenkins.repo http://pkg.jenkins.io/redhat/jenkins.repo
# add key from Jenkins
$ rpm --import https://pkg.jenkins.io/redhat/jenkins.io.key
# install docker-ce
$ amazon-linux-extras install -y docker
# install java, git, jenkins and jq
$ yum install -y java git jenkins jq
# add jenkins to docker group
$ usermod -a -G docker jenkins
# enable and start docker
$ systemctl enable docker && systemctl start docker
# enable and start jenkins
$ systemctl enable jenkins && systemctl start jenkins
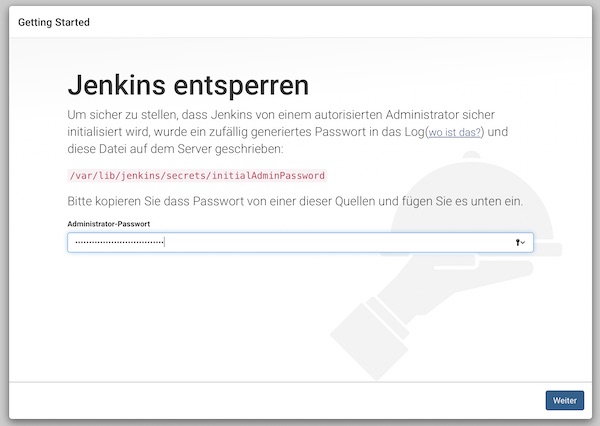
# get initial password
$ cat /var/lib/jenkins/secrets/initialAdminPassword
Note: I have a space after etc, because of security settings of my provider.
Do not close the SSH connection yet. Start your browser and following there the Jenkins installation steps. The URL is similar to your SSH connection – http://<EC2 IP|DNS>:8080. You should see the following screen and paste the initial password there.
On next screen press button “Install suggested plugins” and wait for the screen to create administrator account. Fill in your credentials and finish the installation steps. The remaining configurations (on browser) will be made later.
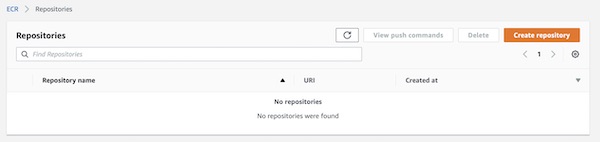
AWS ECR
Before you can push images to ECR, you need to create a new repository. On the ECR page, choose button “Create repository”. Your AWS ECR console screen could look a little bit different.
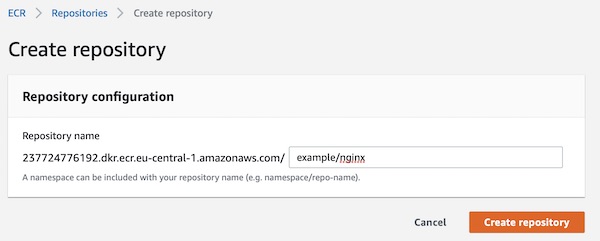
Give a repository name “example/nginx” and press button “Create repository”.
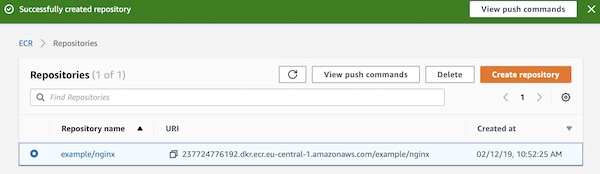
Done, your ECR repository is already created. You can see on overview page all needed informations like Repository name and URI. Your repository URI will be different to my. I will just use the term “<ECR URI>” in my description.
Okay, now enable user jenkins to connect to ECR. Go back to terminal and execute following steps. You need now the credentials from downloaded csv file for “PipelineExampleUser”.
# change to jenkins user
$ su -s /bin/bash jenkins
# show docker info (optional)
$ docker info
# configure AWS-CLI options
$ aws configure
...
AWS Access Key ID [None]: <credentials.csv>
AWS Secret Access Key [None]: <credentials.csv>
Default region name [None]: eu-central-1
Default output format [None]: json
...
# list repositories in registry (optional)
$ aws ecr describe-repositories
Git Repository
I assume that you are familiar with Git. You must now create a Git Repository and create the following folders and files there. I will use my own private GitLab repository.
# show local project tree (optional)
$ tree ~/<path to your project>
|____index.html
|____Dockerfile
|____.gitignore
|____cicd
| |____build.sh
| |____Jenkinsfile
| |____deploy.sh
| |____task_definition.json
| |____test.sh
|____dev_credentials
| |____credentials.csv
|____.git
Note: Please set permission rights for shell scripts like $ chmod +x build.sh deploy.sh test.sh
#!/usr/bin/env bash
## shell options
set -e
set -u
set -f
## magic variables
declare REPONAME
declare ECR
declare REGION
declare BUILD_NUMBER
declare -r -i SUCCESS=0
declare -r -i NO_ARGS=85
declare -r -i BAD_ARGS=86
declare -r -i MISSING_ARGS=87
## script functions
function usage() {
local FILE_NAME
FILE_NAME=$(basename "$0")
printf "Usage: %s [options...]\n" "$FILE_NAME"
printf " -h\tprint help\n"
printf " -n\tset ecr repository name\n"
printf " -e\tset ecr repository uri\n"
printf " -r\tset aws region\n"
printf " -b\tset build number\n "
}
function no_args() {
printf "Error: No arguments were passed\n"
usage
exit "$NO_ARGS"
}
function bad_args() {
printf "Error: Wrong arguments supplied\n"
usage
exit "$BAD_ARGS"
}
function missing_args() {
printf "Error: Missing argument for: %s\n" "$1"
usage
exit "$MISSING_ARGS"
}
## check script arguments
while getopts "hn:e:r:b:" OPTION; do
case "$OPTION" in
h) usage
exit "$SUCCESS";;
n) REPONAME="$OPTARG";;
e) ECR="$OPTARG";;
r) REGION="$OPTARG";;
b) BUILD_NUMBER="$OPTARG";;
*) bad_args;;
esac
done
if [ "$OPTIND" -eq 1 ]; then
no_args
fi
if [ -z "$REPONAME" ]; then
missing_args '-n'
fi
if [ -z "$ECR" ]; then
missing_args '-e'
fi
if [ -z "$REGION" ]; then
missing_args '-r'
fi
if [ -z "$BUILD_NUMBER" ]; then
missing_args '-b'
fi
## run main function
function main() {
local LAST_ID
# delete all previous image(s)
LAST_ID=$(docker images -q "$REPONAME")
if [ -n "$LAST_ID" ]; then
docker rmi -f "$LAST_ID"
fi
# build new image
docker build -t "$REPONAME:$BUILD_NUMBER" --pull=true .
# tag image for AWS ECR
docker tag "$REPONAME:$BUILD_NUMBER" "$ECR":"$BUILD_NUMBER"
# basic auth into ECR
$(aws ecr get-login --no-include-email --region "$REGION")
# push image to AWS ECR
docker push "$ECR":"$BUILD_NUMBER"
}
main
# exit
exit "$SUCCESS"
Inside folder “dev_credentials” I store the credentials.csv from AWS. The content of this folder will be only on my local machine, because via .gitignore I exclude the folder and files from git.
Jenkins job configuration
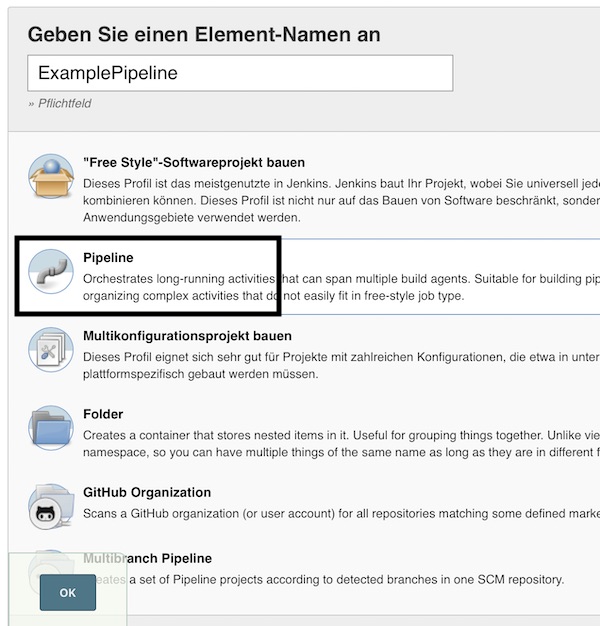
I will not use this tutorial to explain security topics for Jenkins, so we start directly with the configuration of the job (resp. project). On main page press now button “New item” or link “create new jobs”. Insert name “ExamplePipeline”, select “Pipeline” and press button “OK”.
To save some disk space enable checkbox discard old builds (5 builds are enough).
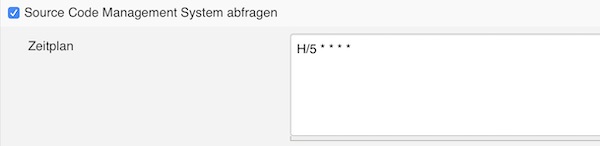
Normally you would create a webhook to trigger the build after commit, but our EC2 instance does change the public IP/DNS on every stop/start. That’s why here we check the revision changes every 5 minutes on git and trigger the job if something has changed.
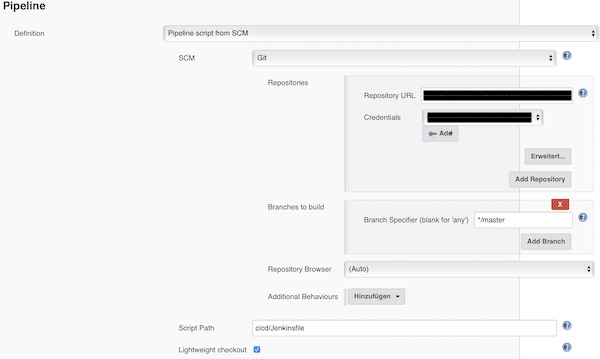
Add the repository (may credentials are needed), configure the branch and Jenkinsfile path.
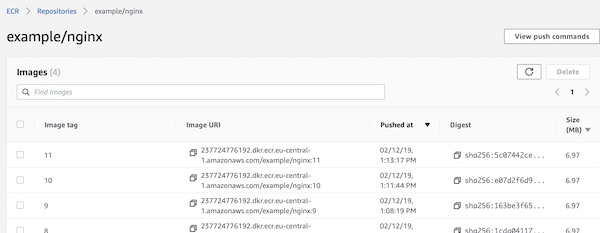
Press button “save”, _cross fingers_ and trigger manual the build. If you did nothing wrong, the job will run without issues and the ECR contains your images (depending how often you trigger the build).
The next part of this tutorial series will be about deployment to ECS.