What’s new? I have received various inquiries as to whether this blog is still being maintained. Yes he still will! Currently, however, a lot has changed in my life and through various security settings of my provider I have created a few tutorials directly on GitHub. So here are 2 categories which I would like to introduce to you.
In this GitHub repository you will find instructions on how to use the small development board as a security analysis device. These instructions are simply intended to show which options the Raspberry PI offers and to provide an introduction to the topic of cyber security.
I love the Adafruit Matrix LED! With a little python you can achieve everything your heart desires super quickly and easily. To make the start a little easier for you, I’ve created a few examples with Python. You are welcome to use these or (even better) develop them further.
More???
I also started to post some pictures and videos of my work on Instagram … Yes, I have to go with time too. 😉
So if you find the time and feel like it, just drop by these platforms and let yourself be inspired for your projects.
Within this tutorial I will explain shortly the combination of GitLab and Sitespeed.io. Normally GitLab provides this feature (Browser Performance Testing) but only with Premium or Silver editions. I imagine for this example that you know already the basics about GitLab pipelines, Docker in Docker and Sitespeed.io.
Preparation
As a first step you create a simple project directory with some files and one folder.
# create project directory
$ mkdir -p ~/Projects/SitespeedGitLab/ci
# change directory
cd ~/Projects/SitespeedGitLab
# create login file
$ vim ci/login.js
# create urls file
$ vim ci/urls.txt
# create pipeline file
$ vim .gitlab-ci.yml
# show structure (optional)
$ tree .
.
|__.gitlab-ci.yml
|__ci
|__login.js
|__urls.txt
Content of files
For the login we use the simplest version of a script which serves as pre script. You can expand it later as needed. If you do not need a login, you do not have to create this file (leave this out later in the command --preScript login.js).
module.exports = async function(context, commands) {
// navigate to login page
await commands.navigate('your domain');
// add values into input fields
await commands.addText.byId('username', 'input by id');
await commands.addText.byId('password', 'input by id');
// find the submit button and click it
await commands.click.byClassName('Button');
// wait to verify that you are logged in (incl. max time)
return commands.wait.byId('specific tag with id',8000);
};
Let’s get to the next file. Here you simply enter all URLs to be checked. Each line represents a URL to be checked which (in our case) always precedes the login. There is also the possibility to login once for all sub-pages as well as various actions on the pages. In this case you would have to script everything (similar to pre/post scripts).
your url one
your url two
your url three
The files urls.txt and login.js have to be mounted inside the container. Therefore we choose the folder “ci”. After the successfully execution this folder will also provide the sitespeed reports.
Pipeline
The last step is the definition of GitLab pipeline. Here now a very simple example for .gitlab-ci.yml, with only one pipeline stage (test) and job (perf_tests). You can also expand this file later as you like (It’s already possible to build Docker images inside).
Okay … done. You can commit/push everything into GitLab. After successfully pipeline run you can access the reports as GitLab pipeline artifacts (but not via repository folder -> because if the job is done the container and reports are gone).
Start ZAP now, if you get asked for select the persistent session – just select option “No, I don’t want…” and press button “Start”.
Select persist ZAP Session
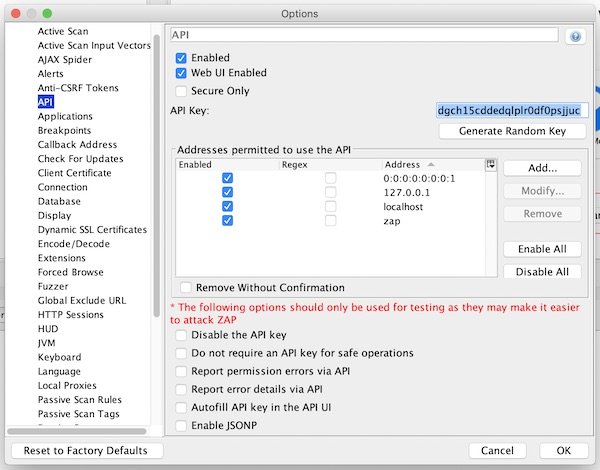
Now open “Preferences” and ensure that ZAP API is enabled.
Enable ZAP API
Our last action for configuration is to enable ZAP Proxy.
ZAP Proxy
Start ZAP via command line
# show help (macOS)
$ /Applications/OWASP\ ZAP.app/Contents/MacOS/OWASP\ ZAP.sh -h
# show default directory (macOS)
$ ls -la ~/Library/Application\ Support/ZAP/
# start ZAP in daemon mode with specific port and apikey (macOS)
$ /Applications/OWASP\ ZAP.app/Contents/MacOS/OWASP\ ZAP.sh -daemon -port 8090 -config api.key=12345
# open ZAP API in browser
$ open http://localhost:8090/UI
# list all sites
$ curl -s "http://localhost:8090/JSON/core/view/sites/?apikey=12345" | jq .
# list all hosts
$ curl -s "http://localhost:8090/JSON/core/view/hosts/?apikey=12345" | jq .
ZAP HTTP Sessions
# list all httpSession sites
$ curl -s "http://localhost:8090/JSON/httpSessions/view/sites/?apikey=12345" | jq .
# create new httpSession
$ curl -s "http://localhost:8090/JSON/httpSessions/action/createEmptySession/?apikey=12345&site=www.webscantest.com:443&session=session1" | jq .
# show active httpSession
$ curl -s "http://localhost:8090/JSON/httpSessions/view/activeSession/?apikey=12345&site=www.webscantest.com:443" | jq .
ZAP Spider scan
# start spider scan
$ curl -s "http://localhost:8090/JSON/spider/action/scan/?apikey=12345&zapapiformat=JSON&formMethod=GET&url=https://www.webscantest.com"
# show spider scan status
$ curl -s "http://localhost:8090/JSON/spider/view/status/?apikey=12345" | jq .
ZAP Context
# list all context
$ curl -s "http://localhost:8090/JSON/context/view/contextList/?apikey=12345" | jq .
# create context
$ curl -s "http://localhost:8090/JSON/context/action/newContext/?apikey=12345&contextName=Default+Context" | jq .
# show specific context
$ curl -s "http://localhost:8090/JSON/context/view/context/?apikey=12345&contextName=Default+Context" | jq .
# add regex into includeInContext
$ curl -s "http://localhost:8090/JSON/context/action/includeInContext/?apikey=12345&contextName=Default+Context&ex=https://www.webscantest.com.*" | jq .
# list all includeRegexs
$ curl -s "http://localhost:8090/JSON/context/view/includeRegexs/?apikey=12345&contextName=Default+Context" | jq .
ZAP Active scan
# start active scan
$ curl -s "http://localhost:8090/JSON/ascan/action/scan/?apikey=12345&zapapiformat=JSON&formMethod=GET&url=https://www.webscantest.com&recurse=&inScopeOnly=false&scanPolicyName=&method=&postData=&contextId="
# show active scan status
$ curl -s "http://localhost:8090/JSON/ascan/view/status/?apikey=12345" | jq .
ZAP alerts and reports
# list alert counts by url
$ curl -s "http://localhost:8090/JSON/alert/view/alertCountsByRisk/?apikey=12345&url=https://www.webscantest.com&recurse=True" | jq .
# list alerts by risk
curl -s "http://localhost:8090/JSON/alert/view/alertsByRisk/?apikey=12345&url=https://www.webscantest.com&recurse=True" | jq .
# show json report
$ curl -s "http://localhost:8090/OTHER/core/other/jsonreport/?apikey=12345" | jq .
# list all alerts
$ curl -s "http://localhost:8090/JSON/core/view/alerts/?apikey=12345" | jq .
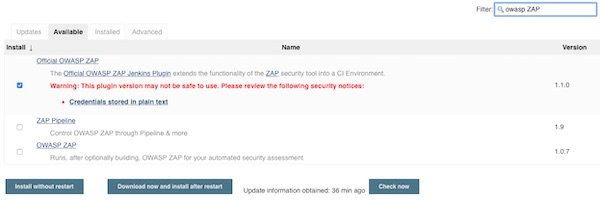
This tutorial will explain how easy you implement ZAP Attack Proxy into Jenkins. Therefor we create a Freestyle job and will use the “Official OWASP ZAP Jenkins Plugin“. That you can follow and reproduce the tutorial, you need a running Jenkins instance with SSH access to it and proper system rights (OS, Jenkins).
Install ZAP Attack Proxy
Following steps needs to be done when SSH connection, to Jenkins, is established.
Note: If you don’t restart Jenkins after creating “ZAPROXY_HOME”, you will run into trouble like “java.lang.IllegalArgumentException: ZAP INSTALLATION DIRECTORY IS MISSING, PROVIDED [ null ]”
Install needed Jenkins PlugIn’s
Search for “OWAS ZAP” and for “HTML Publisher” plugins.
Official OWASP ZAP HTML Publisher
Configure Jenkins Freestyle job
All what we need is there, we can start to setup a Jenkins “Freestyle project” with the name “ZAPAttackProxy”.
Jenkins Freestyle Project
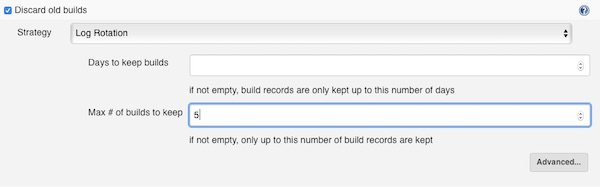
The next setting is optional… I recommend to find your own value (I go with 5 for that example).
Max # of builds to keep
On every build (Jenkins job run) the workspace should be clean. Please enable the checkbox.
Delete workspace before build starts
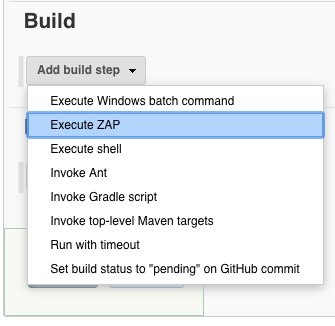
We add now the build step. This build step is available because of the PlugIn “Official OWASP ZAP“.
Build step: Execute ZAP
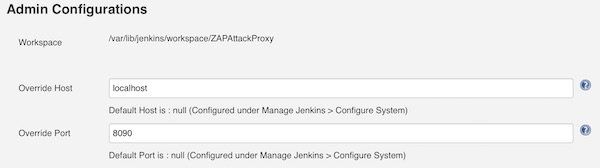
Now we have many fields to configure. We start to set the values for section “Admin Configurations”.
Admin Configuration
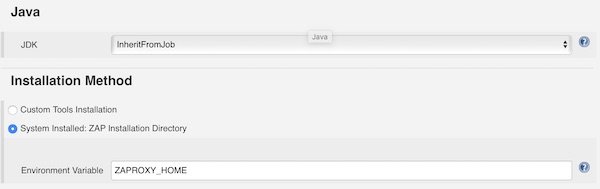
As we already installed ZAP and created the entry into /etc/environment, we can now use that variable.
Installation Method
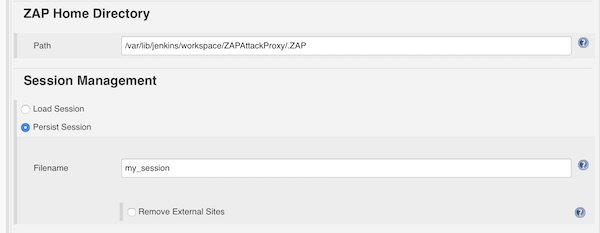
For ZAP Home Directory we add the path to the workspace and let the build create the directory “.ZAP”. For Session Management we choose “Persist Session” and give filename “my_session”.
Home Directory & Session Management
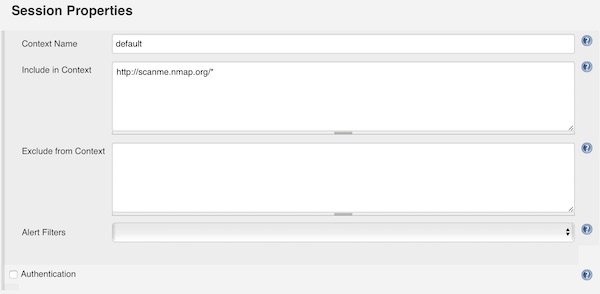
Under section “Session Properties” you add the Context Name “default” and for “Include in Context” you can add IP’s and/or Domains. For that example I choose “http://scanme.nmap.org/*”.
Session Properties
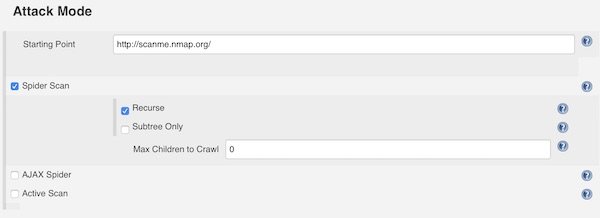
In section “Attack Method” you can choose different attack methods like Spider Scan and so on. Please set always a “Starting Point”. The settings here are self explainable.
Attack Method
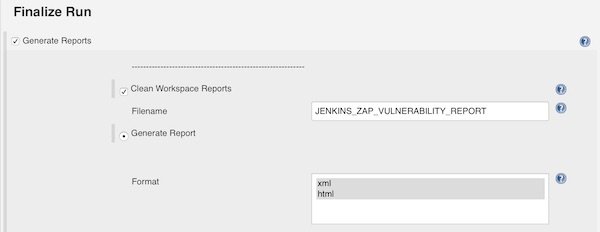
Enable checkbox “Generate Reports” in section “Finalize Run”. Now enter a filename and select “XML” and “HTML” format.
Finalize Run
Note: You can ignore the HTTP 404 error.
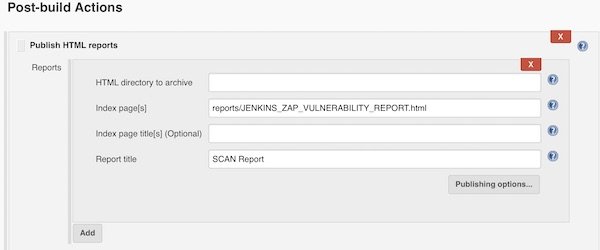
We are done! To provide on our job dashboard a link for HTML report, you can use now the HTML Publisher.
Nessus is a vulnerability scanner from Tenable. In this tutorial I will show how you can install Nessus on AWS (Debian), how you connect your local browser and perform a simple network scan. You need only a AWS account (eq Free Tier), SSH and a web browser.
Note: Please have a look on that page about pentesting on AWS first.
Create new EC2 instance
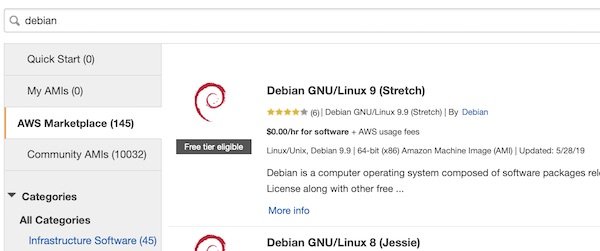
Login into your AWS console (or use AWSCLI), create a new SecurityGroup with SSH port 22 only (inbound) and launch a new instance. Search for “Debian”…
Debian 9 on AWS Maretplace
Press button “Select” and finish all needed following steps (save your keys). After your EC2 instance is ready check for IP or DNS and connect.
# connect via SSH to EC2 instance
$ ssh -i ~/.ssh/ admin@<instance>
# compile a list of locale definition files (optional)
$ sudo locale-gen UTF-8
Install Nessus
Open download page and select latest version for Debian (as I wrote this tutorial it was Nessus-8.5.1-debian6_amd64.deb). Confirm and download. Via SCP, in new terminal, you can upload the file to your EC2 instance.
# copy file from local to remote
$ scp -i ~/.ssh/ ~/Downloads/Nessus-8.5.1-debian6_amd64.deb admin@<instance>:/tmp
Back to instance terminal … Now install and start Nessus.
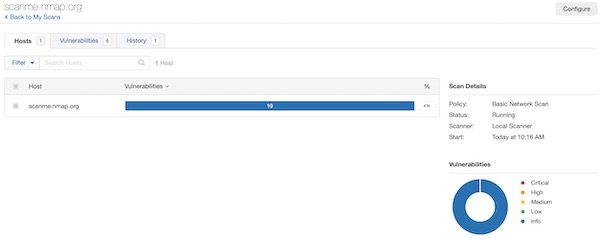
When the initialization has been completed successfully, login and create a new scan. Select “Basic Network Scan” and add URL: http://scanme.nmap.org. Select “Basic Network Scan” and “Port scan (common ports)” for scan settings. Save and start your created scan. Please be patient, the scan will take a while.
Running Nessus scan
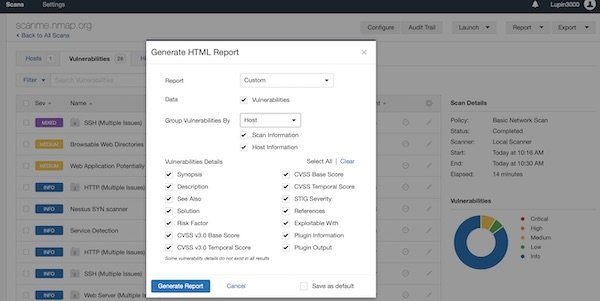
Create a scan report
After a while, the scan is complete. Now you can create a “Custom” report. BTW … feature is only available for completed scans. So select “Export” – “Custom” and generate the report.
Apache Guacamole … What is it about? It’s a client-less remote gateway for Telnet, SSH, RDP and VNC. Client-less, because there is no need to install any plugin or additional software for users (clients). The client will use just the browser (also without any plugin). In this tutorial we will create a very simple environment via Vagrant and use Guacamole. Why the tutorial? Because I know a lot of testers for example – who work with Windows, who are not allowed to install any software (eq Putty) but still need access to environments. … Next point are for example public security groups on cloud providers. Here only one port would be needed to support different protocols on different hosts (incl. file transfer).
Okay, via your favorite editor you now add the content of all files. All files inside directory “src” are configuration files (installed on Guacamole host).
# Hostname and port of guacamole proxy
guacd-hostname: localhost
guacd-port: 4822
available-languages: en, de
auth-provider: net.sourceforge.guacamole.net.basic.BasicFileAuthenticationProvider
basic-user-mapping: /etc/guacamole/user-mapping.xml
The ShellProvisioner.sh includes all installation and configuration for Guacamole All examples are provided but for Debian RDP is currently not working and I commented out.
First start-up the environment (via simple Vagrant command) and next start the VNC inside the box. You can do via vagrant ssh or you start the VNC via Browser (SSH).
# start environment (be patient)
$ vagrant up
# show status (optional)
$ vagrant status
# ssh into 2nd box
$ vagrant ssh debian-2-guacamole
# start VNC server on user vagrant
$ vncserver
# Password: vagrant
# Verify: vagrant
# Would you like to enter a view-only password (y/n)? n
# exit ssh into box
$ exit
# open browser with URL
$ open http://localhost:55555/guacamole
Now login with “USERNAME/PASSWORD” (see src/user-mapping.xml) on http://localhost:55555/guacamole. If everything works it should look like this:
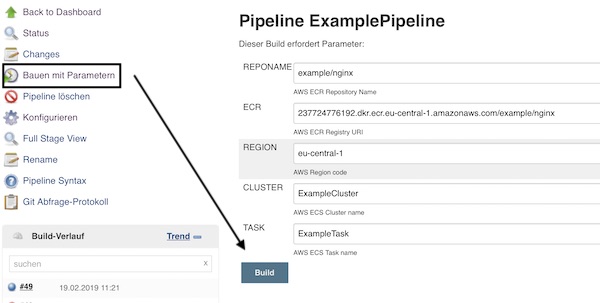
Okay,… The pipeline has already two steps “Build” and “Deploy” running, but the last step “Test” is missing. In this part I will show a simple example with Python, Selenium and Docker (standalone-chrome) for test step.
#!/usr/bin/env bash
## shell options
set -e
set -u
set -f
## magic variables
declare CLUSTER
declare TASK
declare TEST_URL
declare -r -i SUCCESS=0
declare -r -i NO_ARGS=85
declare -r -i BAD_ARGS=86
declare -r -i MISSING_ARGS=87
## script functions
function usage() {
local FILE_NAME
FILE_NAME=$(basename "$0")
printf "Usage: %s [options...]\n" "$FILE_NAME"
printf " -h\tprint help\n"
printf " -c\tset esc cluster name uri\n"
printf " -t\tset esc task name\n"
}
function no_args() {
printf "Error: No arguments were passed\n"
usage
exit "$NO_ARGS"
}
function bad_args() {
printf "Error: Wrong arguments supplied\n"
usage
exit "$BAD_ARGS"
}
function missing_args() {
printf "Error: Missing argument for: %s\n" "$1"
usage
exit "$MISSING_ARGS"
}
function get_test_url() {
local TASK_ARN
local TASK_ID
local STATUS
local HOST_PORT
local CONTAINER_ARN
local CONTAINER_ID
local INSTANCE_ID
local PUBLIC_IP
# list running task
TASK_ARN="$(aws ecs list-tasks --cluster "$CLUSTER" --desired-status RUNNING --family "$TASK" | jq -r .taskArns[0])"
TASK_ID="${TASK_ARN#*:task/}"
# wait for specific container status
STATUS="PENDING"
while [ "$STATUS" != "RUNNING" ]; do
STATUS="$(aws ecs describe-tasks --cluster "$CLUSTER" --task "$TASK_ID" | jq -r .tasks[0].containers[0].lastStatus)"
done
# get container id
CONTAINER_ARN="$(aws ecs describe-tasks --cluster "$CLUSTER" --tasks "$TASK_ID" | jq -r .tasks[0].containerInstanceArn)"
CONTAINER_ID="${CONTAINER_ARN#*:container-instance/}"
# get host port
HOST_PORT="$(aws ecs describe-tasks --cluster "$CLUSTER" --tasks "$TASK_ID" | jq -r .tasks[0].containers[0].networkBindings[0].hostPort)"
# get instance id
INSTANCE_ID="$(aws ecs describe-container-instances --cluster "$CLUSTER" --container-instances "$CONTAINER_ID" | jq -r .containerInstances[0].ec2InstanceId)"
# get public IP
PUBLIC_IP="$(aws ec2 describe-instances --instance-ids "$INSTANCE_ID" | jq -r .Reservations[0].Instances[0].PublicIpAddress)"
TEST_URL="$(printf "http://%s:%d" "$PUBLIC_IP" "$HOST_PORT")"
}
function clean_up() {
# stop container
if [ "$(docker inspect -f {{.State.Running}} ChromeBrowser)" == "true" ]; then
docker rm -f ChromeBrowser
fi
# delete virtualenv
if [ -d .env ]; then
rm -fr .env
fi
}
function run_selenium_test() {
local TEST_TEMPLATE
local TEST_FILE
# clean up
clean_up
# pull image (standalone-chrome)
docker pull selenium/standalone-chrome
# run docker container (standalone-chrome)
docker run -d -p 4444:4444 --name ChromeBrowser selenium/standalone-chrome
# create and activate virtualenv
virtualenv .env && source .env/bin/activate
# install Selenium
pip install -U selenium
# read test template into variable
TEST_TEMPLATE=$(cat ./test/example.py)
# replace string with URL
TEST_FILE="${TEST_TEMPLATE/APPLICATION_URL/$TEST_URL}"
# save into final test file
echo "$TEST_FILE" > ./test/suite.py
# execute test
python -B ./test/suite.py
# deactivate virtualenv
deactivate
}
## check script arguments
while getopts "hc:t:" OPTION; do
case "$OPTION" in
h) usage
exit "$SUCCESS";;
c) CLUSTER="$OPTARG";;
t) TASK="$OPTARG";;
*) bad_args;;
esac
done
if [ "$OPTIND" -eq 1 ]; then
no_args
fi
if [ -z "$CLUSTER" ]; then
missing_args '-c'
fi
if [ -z "$TASK" ]; then
missing_args '-t'
fi
## run main function
function main() {
get_test_url
printf "Test Application URL: %s\n" "$TEST_URL"
run_selenium_test
}
main
# exit
exit "$SUCCESS"
Ensure that “example.py” has all needed permission rights. $ chmod +x example.py Commit all changes now and wait that the Jenkins job gets triggered (or trigger manually).
That’s already all… your job should execute all steps. This part is done super fast. 😉
Some last words
There is a lot of space for improvements here, but I think you learned already much and had some fun. Some hints now:
you can add any other test methods by your self on this step (eq. Performance- and Security tests)
Unit tests and Static Code Analysis could executed on build step (before create image)
check out AWS ECS Services
use a proxy for Jenkins and enable SSL
create other pipelines and ECS clusters to enable staging
create “Lifecycle policy rules” on ECR
use Git Webhook’s to trigger the Jenkins jobs
add a post step in your Jenkins pipeline to store metrics and/or inform about build status
In previous tutorial I showed you how to create the environment and how to implement the build steps for Jenkins pipeline. Now I will show you to setup the deploy step.
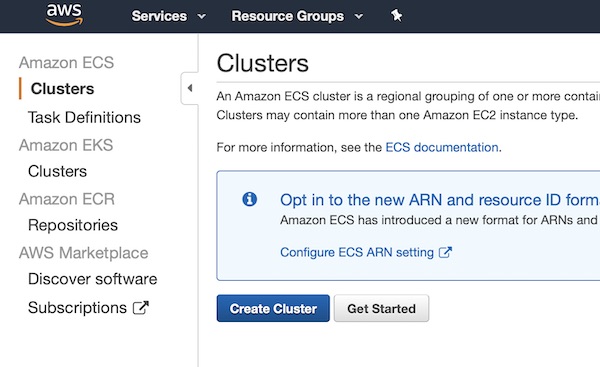
Create a very small AWS ECS cluster in region “Frankfurt” (eu-central-1). Therefore enter Amazon ECS Clusters and press button “Create Cluster”.
Select template “EC2 Linux + Networking” and continue to next step.
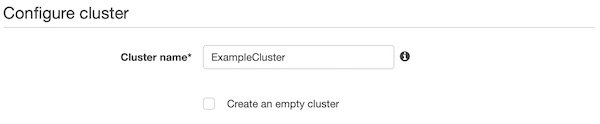
On section “Configure cluster” you give a name like “ExampleCluster”.
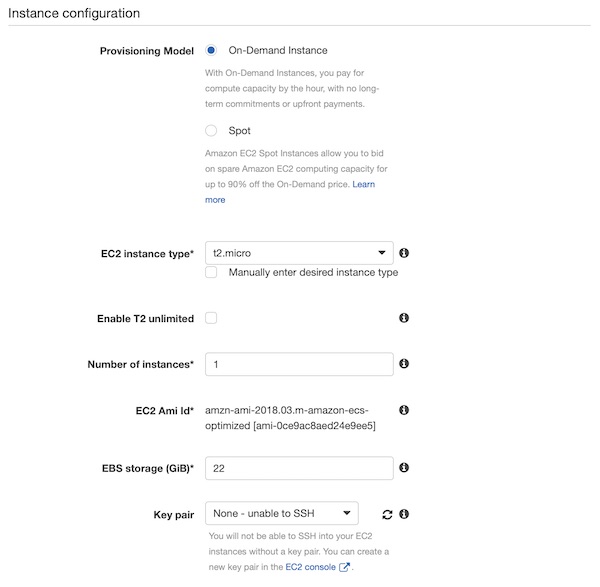
On section “Instance configuration” select “On-Demand Instance”, “t2.micro”, “1”, “22” and “None – unable to SSH”.
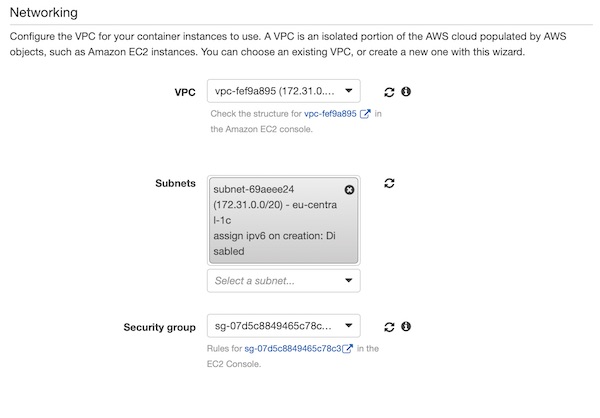
In the section “Networking” you have to be careful now. Your values will be different from mine! Under VPC, select the same value as for the EC2 Jenkins instance (I selected default VPC). Now you can choose one of the subnets. We created the security group together with the EC2 Jenkins instance, so select “ExampleSecurityGroup” here.
Okay, press button “Create” and wait till the cluster is created. The cluster creation can take a while, so please be patient.
AWS ECS Task Definition
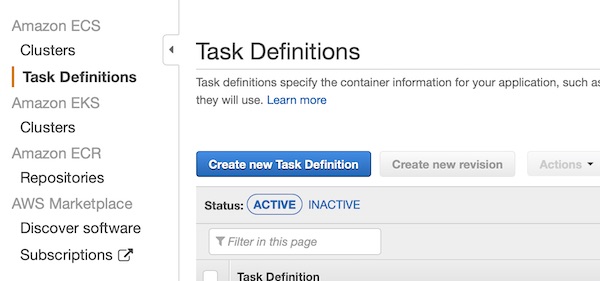
The cluster is running and the “Task Definition” can be created. So press button “Create new Task Definition”.
Select “EC2” on page launch type compatibility and press button “Next step”.
On section “Configure task and container definitions” set value “ExampleTask” for input field “Task Definition Name” and for “Network Mode” select “<default>”.
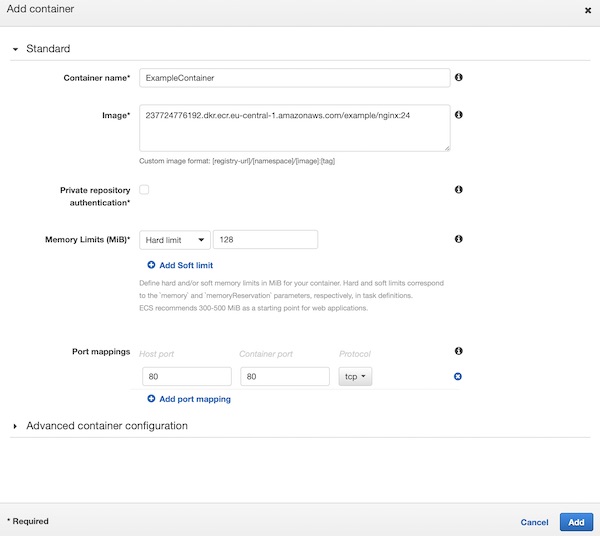
On section “Container Definition” press button “Add Container”. A new window will slide in. Here give the “Container name” value “ExampleContainer”, add under image your latest version from ECR (my latest is 24). Set values “128” for “Memory Limits (MiB)”, “80:80” for “Port mappings” and press button “Add”.
You are done with your task definition configuration, scroll down and press button “Create”.
AWS IAM
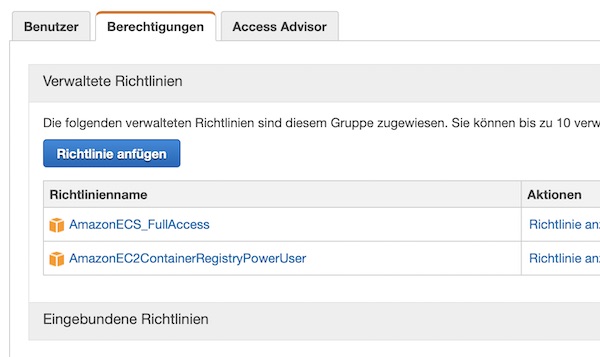
Before we can go through the next steps, we need to adjust the group policy for “PipelineExampleGroup”. You must add the “AmazonECS_FullAccess” policy. _For our example this is okay, but never use this policy in production!_
Run task on ECS cluster (via Jenkins)
Now you only need to modify two files in your repository. Replace the content of “deploy.sh” and “Jenkinsfile” with following contents.
#!/usr/bin/env bash
## shell options
set -e
set -u
set -f
## magic variables
declare ECR
declare CLUSTER
declare TASK
declare BUILD_NUMBER
declare -r -i SUCCESS=0
declare -r -i NO_ARGS=85
declare -r -i BAD_ARGS=86
declare -r -i MISSING_ARGS=87
## script functions
function usage() {
local FILE_NAME
FILE_NAME=$(basename "$0")
printf "Usage: %s [options...]\n" "$FILE_NAME"
printf " -h\tprint help\n"
printf " -e\tset ecr repository uri\n"
printf " -c\tset esc cluster name uri\n"
printf " -t\tset esc task name\n"
printf " -b\tset build number\n "
}
function no_args() {
printf "Error: No arguments were passed\n"
usage
exit "$NO_ARGS"
}
function bad_args() {
printf "Error: Wrong arguments supplied\n"
usage
exit "$BAD_ARGS"
}
function missing_args() {
printf "Error: Missing argument for: %s\n" "$1"
usage
exit "$MISSING_ARGS"
}
## check script arguments
while getopts "he:c:t:b:" OPTION; do
case "$OPTION" in
h) usage
exit "$SUCCESS";;
e) ECR="$OPTARG";;
c) CLUSTER="$OPTARG";;
t) TASK="$OPTARG";;
b) BUILD_NUMBER="$OPTARG";;
*) bad_args;;
esac
done
if [ "$OPTIND" -eq 1 ]; then
no_args
fi
if [ -z "$ECR" ]; then
missing_args '-e'
fi
if [ -z "$CLUSTER" ]; then
missing_args '-c'
fi
if [ -z "$TASK" ]; then
missing_args '-t'
fi
if [ -z "$BUILD_NUMBER" ]; then
missing_args '-b'
fi
## run main function
function main() {
local TASK_ARN
local TASK_ID
local ACTIVE_TASK_DEF
local TASK_DEFINITION
local TASK_DEF_ARN
# list running task
TASK_ARN="$(aws ecs list-tasks --cluster "$CLUSTER" --desired-status RUNNING --family "$TASK" | jq -r .taskArns[0])"
TASK_ID="${TASK_ARN#*:task/}"
# stop running task
if [ -n "$TASK_ID" ] && [ "$TASK_ID" != "null" ]; then
printf "INFO: Stop Task %s\n" "$TASK_ID"
aws ecs stop-task --cluster "$CLUSTER" --task "$TASK_ID"
fi
# list active task definition
ACTIVE_TASK_DEF="$(aws ecs list-task-definitions --family-prefix "$TASK" --status ACTIVE | jq -r .taskDefinitionArns[0])"
# derigister task definition
if [ -n "$ACTIVE_TASK_DEF" ]; then
printf "INFO: Deregister Task Definition %s\n" "$ACTIVE_TASK_DEF"
aws ecs deregister-task-definition --task-definition "$ACTIVE_TASK_DEF"
fi
# read task definition template
TASK_DEFINITION=$(cat ./cicd/task_definition.json)
# create new task definition file
TASK_DEFINITION="${TASK_DEFINITION/URI/$ECR}"
echo "${TASK_DEFINITION/NUMBER/$BUILD_NUMBER}" > ecs_task_definition.json
# register new task definition
TASK_DEF_ARN="$(aws ecs register-task-definition --cli-input-json file://ecs_task_definition.json | jq -r .taskDefinition.taskDefinitionArn)"
# run task by task definition
aws ecs run-task --task-definition "$TASK_DEF_ARN" --cluster "$CLUSTER"
}
main
# exit
exit "$SUCCESS"
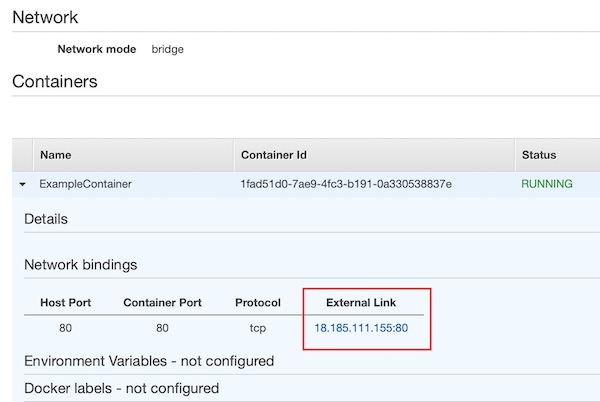
Commit your changes and wait for build trigger (or trigger manually). After successful deployment, your ECS cluster will have a running task now. On section “Container” you can see the link.
Every time when you modify files and commit them into your Git repository, the pipeline will be triggered and latest version will be visible in browser.
That’s it with this part of the series. Cu soon in next part.