If you are testing REST , it happens that you need to prettify JSON. With Python you do not need any other tool except your terminal!
Example
{"glossary":{"title":"example glossary","GlossDiv":{"title":"S","GlossList":{"GlossEntry":{"ID":"SGML","SortAs":"SGML","GlossTerm":"Standard Generalized Markup Language","Acronym":"SGML","Abbrev":"ISO 8879:1986","GlossDef":{"para":"A meta-markup language, used to create markup languages such as DocBook.","GlossSeeAlso":["GML","XML"]},"GlossSee":"markup"}}}}}
Now open you terminal…
# Using module json.tool to prettify and validate
$ cat example.json | python -m json.tool
{
"glossary": {
"GlossDiv": {
"GlossList": {
"GlossEntry": {
"Abbrev": "ISO 8879:1986",
"Acronym": "SGML",
"GlossDef": {
"GlossSeeAlso": [
"GML",
"XML"
],
"para": "A meta-markup language, used to create markup languages such as DocBook."
},
"GlossSee": "markup",
"GlossTerm": "Standard Generalized Markup Language",
"ID": "SGML",
"SortAs": "SGML"
}
},
"title": "S"
},
"title": "example glossary"
}
}
from xmlrunner import xmlrunner
""" code for test suite ... """
xmlrunner.XMLTestRunner(verbosity=2, output='reports').run(test_suite)
Jenkins
On Jenkins add a new “post-build” action and select the Publish JUnit test result report. Add now the string “reports/*.xml” into the “Test report XMLs” field.
DDT (Data-driven Testing) with Python Selenium Webdriver is very easy! DDT becomes very useful if you have test cases that contains the same test steps. All values could outsourced into files or databases. This tutorial use CSV files.
Precondition
Python installed
selenium and ddt library installed
Example
The folder structure for this tutorial looks like:
Into folder “data” we store the csv files. The packages “library” include a function to read the specific csv files and the package “scenarios” include the test cases. The test suite is on root folder.
#!/usr/bin/env python
# -*- coding: utf8 -*-
import unittest
from scenarios.scenario_a import TestScenarioA
# load test cases
scenario_a = unittest.TestLoader().loadTestsFromTestCase(TestScenarioA)
# create test suite
test_suite = unittest.TestSuite([scenario_a])
# execute test suite
unittest.TextTestRunner(verbosity=2).run(test_suite)
Into the “testsuite.py” we add all test cases provided by scenario package.
#!/usr/bin/env python
# -*- coding: utf8 -*-
import csv
def get_csv_data(csv_path):
"""
read test data from csv and return as list
@type csv_path: string
@param csv_path: some csv path string
@return list
"""
rows = []
csv_data = open(str(csv_path), "rb")
content = csv.reader(csv_data)
# skip header line
next(content, None)
# add rows to list
for row in content:
rows.append(row)
return rows
Just for read the csv and return the values as a list.
You are done with your work and push all into Git. The Build-Server starts his work and all test scripts are failing. Short look and it is clear – certificate errors. The next example shows, how to ignore certificate errors on PhantomJS.
@classmethod
def setUpClass(cls):
"""starting point for test cases"""
cls.driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true'])
cls.driver.implicitly_wait(30)
cls.driver.set_window_size(1024, 768)
cls.driver.get(cls.url)
One way of finding out subdomains are wordlists. Knockpy offers exactly this possibility! It is written in Python, easy to install and to use. The usage of own wordlists is possible, too. The output displayed in the terminal and saved in CSV file.
Precondition
Python installed
Installation
# install with pip
$ sudo pip install https://github.com/guelfoweb/knock/archive/knock3.zip
Usage
# usage with internal wordlist
$ knockpy domain.com
# usage with own wordlist
$ knockpy domain.com -w wordlist.txt
# resolve domain name
$ knockpy -r domain.com
# check zone transfer
$ knockpy -r domain.com
As a penetration tester you may need to check your FTP Server(s). One possibilty is brute-force passwords to auditing. This tutorial show you how easy you can use Python to create such a tool.
This time is shown how to automate performance test for web sites. Tools in usage are Python Selenium WebDriver and BrowserMob proxy. The results are HAR files which can be viewed in HAR Viewer.
Precondition
JAVA installed
Python Packages for selenium and browsermob-proxy
selenium
browsermob-proxy
Preparation
Download BrowserMob Proxy and check if proxy can started by command-line.
# change to
$ cd browsermob-proxy-2.1.0-beta-1/bin/
# start proxy on port 9090
$ ./browsermob-proxy -port 9090
Create Python Class
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""Python - BrowserMob - WebDriver"""
from browsermobproxy import Server
from selenium import webdriver
import json
class CreateHar(object):
"""create HTTP archive file"""
def __init__(self, mob_path):
"""initial setup"""
self.browser_mob = mob_path
self.server = self.driver = self.proxy = None
@staticmethod
def __store_into_file(title, result):
"""store result"""
har_file = open(title + '.har', 'w')
har_file.write(str(result))
har_file.close()
def __start_server(self):
"""prepare and start server"""
self.server = Server(self.browser_mob)
self.server.start()
self.proxy = self.server.create_proxy()
def __start_driver(self):
"""prepare and start driver"""
profile = webdriver.FirefoxProfile()
profile.set_proxy(self.proxy.selenium_proxy())
self.driver = webdriver.Firefox(firefox_profile=profile)
def start_all(self):
"""start server and driver"""
self.__start_server()
self.__start_driver()
def create_har(self, title, url):
"""start request and parse response"""
self.proxy.new_har(title)
self.driver.get(url)
result = json.dumps(self.proxy.har, ensure_ascii=False)
self.__store_into_file(title, result)
def stop_all(self):
"""stop server and driver"""
self.server.stop()
self.driver.quit()
if __name__ == '__main__':
path = "browsermob-proxy-2.1.0-beta-1/bin/browsermob-proxy"
RUN = CreateHar(path)
RUN.start_all()
RUN.create_har('google', 'http://google.com')
RUN.create_har('stackoverflow', 'http://stackoverflow.com')
RUN.stop_all()
Note: The highlighted line must contain the path to BrowserMob Proxy! Happy testing! If you use PhantomJS instead of Firefox, you can use this on Build server like Jenkins/Hudson and so on, too.
It is time again for an extensive tutorial. This time, a tiny test application for passive and active information gathering. After the instruction you are welcome to improve the application with more features! Okay let’s start…
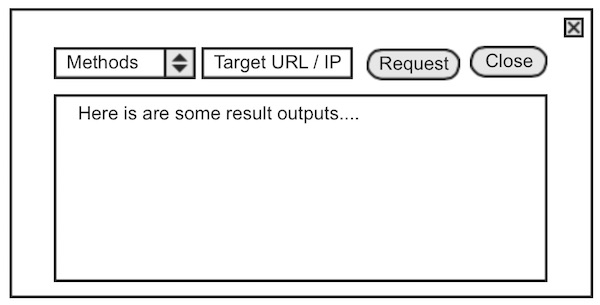
What should it do?
The security tester selects a information gathering method first. As second step the testers insert the URL or IP in a testfield and press a button. The result should printed out in a text area. The GUI should look like this:
How it is implemented?
The prefered language is Python 2.7. So it is portable to different OS and for the most of methods are already packages available. The GUI is done with Tkinter. Tkinter provides all objects which are needed as widgets and ranges for this scope out completely. The file and folder structure look like: