Today an basic introduction to Jenkins, InfluxDB and Grafana. Docker is used to save some time. Okay,… let’s start.
Preparation
# create project and change directory $ mkdir ~/Projects/JIG/influxdb && cd ~/Projects/JIG/ # download official jenkins image (latest) $ docker pull jenkins # download official influxdb image (latest) $ docker pull influxdb # download official grafana image (latest) $ docker pull grafana/grafana # list docker images $ docker images ... REPOSITORY TAG IMAGE ID CREATED SIZE jenkins latest 59b08e8f6e37 4 days ago 704 MB grafana/grafana latest 2cdb407c0fa4 7 days ago 286 MB influxdb latest fad81160f2de 13 days ago 224 MB ...
Jenkins preparation
# start Jenkins $ docker run --name jenkins -p 8080:8080 jenkins # copy password from cli ... ************************************************************* Jenkins initial setup is required. An admin user has been created and a password generated. Please use the following password to proceed to installation: b49ffa5749724d61b43d3a159b181133 ...
Now open your favorite browser with URL http://localhost:8080 and unlook Jenkins with following steps.
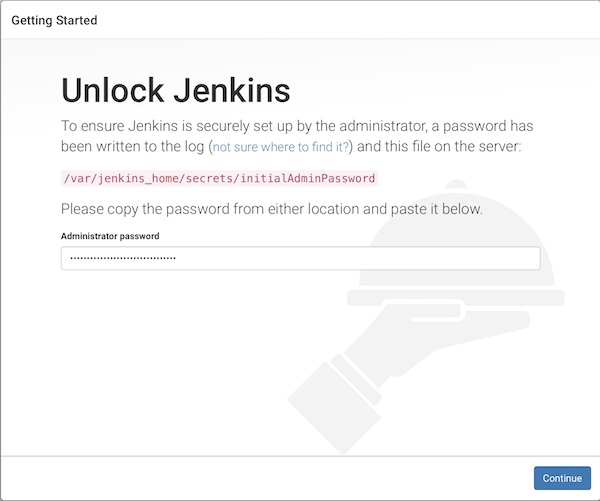
- unlook with password from cli
- install suggested plugins
- create your admin user
- start using jenkins
Next, the InfluxDB plug-in must be installed.
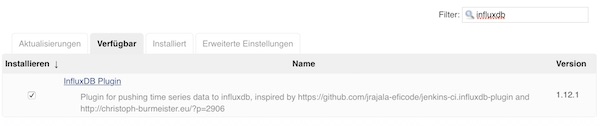
InfluxDB preparation
# start InfluxDB
$ docker run --name influxdb -p 8086:8086 -v $PWD/influxdb:/var/lib/influxdb influxdb
# check current configuration (optional)
$ docker exec -i influxdb influxd config
# create new user
$ curl -G http://localhost:8086/query --data-urlencode "q=CREATE USER jenkins WITH PASSWORD 'password123' WITH ALL PRIVILEGES"
# create database for jenkins
$ curl -G http://localhost:8086/query -u jenkins:password123 --data-urlencode "q=CREATE DATABASE jenkins_db"
# show users (optional)
$ curl -G http://localhost:8086/query -u jenkins:password123 --data-urlencode "q=SHOW USERS"
...
{"results":[{"statement_id":0,"series":[{"columns":["user","admin"],"values":[["jenkins",true]]}]}]}
...
# show databases (optional)
$ curl -G http://localhost:8086/query -u jenkins:password123 --data-urlencode "q=SHOW DATABASES"
...
{"results":[{"statement_id":0,"series":[{"name":"databases","columns":["name"],"values":[["_internal"],["jenkins_db"]]}]}]}
...
# show measurements
$ curl -G http://localhost:8086/query -u jenkins:password123 --data-urlencode "db=jenkins_db" --data-urlencode "q=SHOW MEASUREMENTS"
...
{"results":[{"statement_id":0}]}
...Connect Jenkins with InfluxDB
# start jenkins container (if stopped)
$ docker start jenkins
# show ip of influxdb container
$ docker inspect --format '{{ .NetworkSettings.IPAddress }}' influxdb
...
172.17.0.2
...Add new InfluxDB target on Jenkins
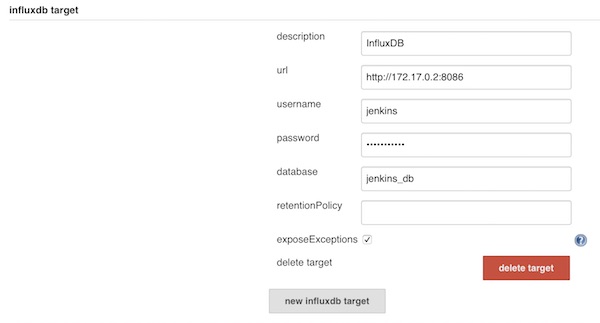
Save and create a new freestyle job. For example with following configuration.
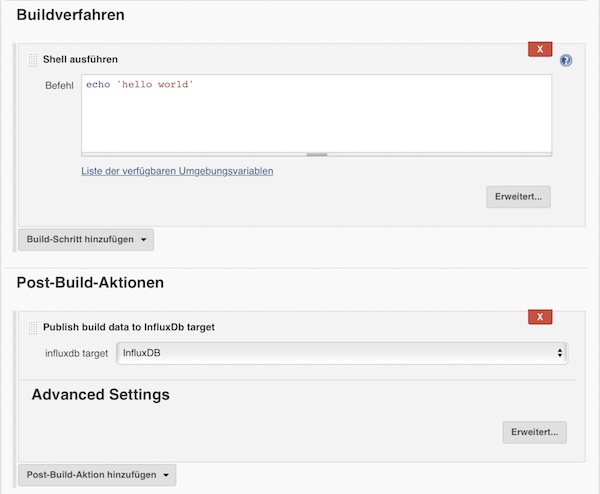
When you are done, run the job.
# show measurements
$ curl -G http://localhost:8086/query -u jenkins:password123 --data-urlencode "db=jenkins_db" --data-urlencode "q=SHOW MEASUREMENTS"
...
{"results":[{"statement_id":0,"series":[{"name":"measurements","columns":["name"],"values":[["jenkins_data"]]}]}]}
...
# run select statement (optional)
$ curl -G http://localhost:8086/query -u jenkins:password123 --data-urlencode "db=jenkins_db" --data-urlencode "q=SELECT * FROM jenkins_data"
...
{"results":[{"statement_id":0,"series":[{"name":"jenkins_data","columns":["time","build_number","build_result","build_result_ordinal","build_status_message","build_successful","build_time","last_stable_build","last_successful_build","project_build_health","project_name","project_name_1"],"values":[["2017-06-08T17:27:24.487Z",9,"SUCCESS",0,"stable",true,16,9,9,100,"test","test"]]}]}]}
...Add Grafana
# start containers (if stopped) $ docker start influxdb && docker start jenkins # run grafana container $ docker run --name grafana -i -p 3000:3000 grafana/grafana
Open you browser with URL http://localhost:3000, login with credentials (admin/admin) and add a new InfluxDB data source.
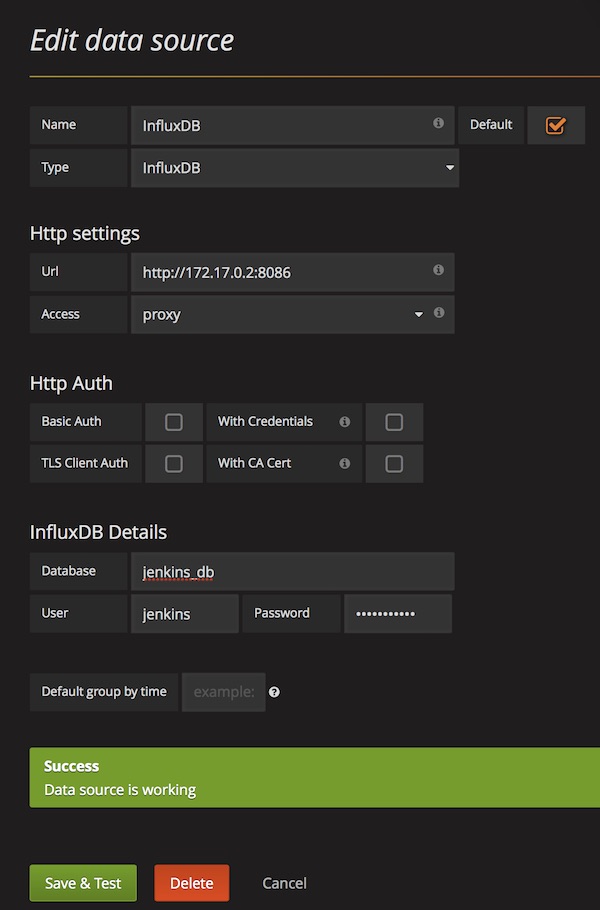
From now on, you can create and share dashboards in Grafana, which shows all Jenkins metrics.